Seeking guidance in choosing and evaluating R packages
By Julia Silge
August 8, 2017
At useR!2017 in Brussels last month, I contributed to an organized session focused on navigating the 11,000+ packages on CRAN. My collaborators on this session and I recently put together an overall summary of the session and our goals, and now I’d like to talk more about the specific issue of learning about R packages and deciding which ones to use. John and Spencer will write more soon about the two other issues of our focus:
- meta-packages that can unify multiple packages within domains and
- searching for packages.
In preparation for this session, I ran a brief online survey in the spring of 2017 to ask R users how they currently discover and learn about R packages. The results of this survey are available in an R package (SO META) on GitHub.
library(packagesurvey)
data(package_survey)There were 1039 respondents to the survey. You can easily explore how many respondents chose each answer to the single question on the survey, “How do you currently discover and learn about R packages?”
library(tidyverse)
package_survey %>%
mutate(total = n_distinct(respondent)) %>%
count(answer, total) %>%
arrange(desc(n)) %>%
mutate(proportion = scales::percent(n / total)) %>%
select(-total, -n) %>%
kable(col.names = c("How do you currently discover and learn about R packages?",
"% of respondents who chose each answer"))| How do you currently discover and learn about R packages? | % of respondents who chose each answer |
|---|---|
| Social media such as blogs, R-bloggers, Twitter, Slack, or GitHub contacts | 79.8% |
| General search websites such as Google and Yahoo | 57.0% |
| Your personal network, such as colleagues and professors | 41.6% |
| Books, textbooks, or journal articles (JSS, JOSS, R-Journal) | 31.9% |
| Conferences, meet-ups, or seminars | 24.1% |
| CRAN Task Views | 21.8% |
| Email lists such as r-help, r-packages, or r-pkg-devel | 15.3% |
| R-specific search websites such as METACRAN (www.r-pkg.org) or Rdocumentation (https://www.rdocumentation.org/) | 11.1% |
| Other (send ideas to @juliasilge on Twitter!) | 4.2% |
| R packages built for search such as the sos package | 2.2% |
Responses to this survey were fielded from R email help lists, local R meetup groups, social media such as Twitter, and affinity groups such as R-Ladies. The respondents to this survey overwhelmingly look to social media including blogs and Twitter to learn about R packages, and also make use of general search sites and their personal network. I know this aligns with how I personally learn about R packages!
I heard some great and insightful answers from people contributing to the “other” option. R users use Stack Overflow to learn about R packages, as well as options like CRANberries and crantastic, both of which have RSS feeds that users follow. Other users mentioned learning by reading code on GitHub (this is one I have done too!), and other search websites including rpackages.io.
You might also be interested in when R users responded to the survey.
package_survey %>%
distinct(respondent, .keep_all = TRUE) %>%
ggplot(aes(response_time)) +
geom_histogram(fill = "midnightblue") +
labs(x = NULL,
y = "Number of R users",
title = "Responses to survey on package discovery over time")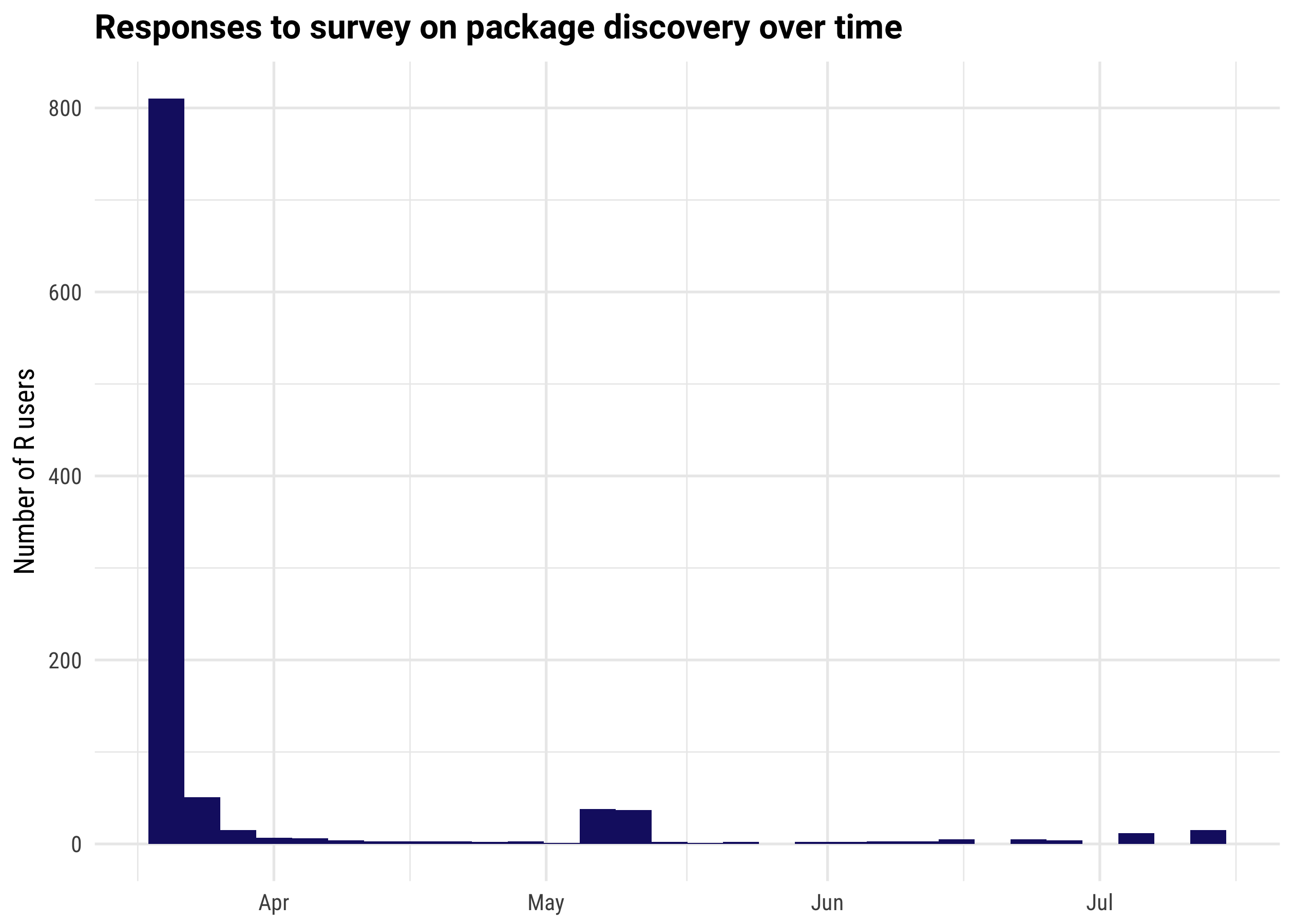
At useR, after the large combined session, we broke out into three smaller sessions for discussion and brainstorming. I facilitated the breakout session focused on guidance for package choice and package evaluation. We had about 40 participants in our discussion on choosing and evaluating R packages. It was a fruitful discussion and several important themes emerged.
The Value of Personal Impact
Participants in our session emphasized how impactful personal relationships can be in how packages are shared and evaluated. Some participants discussed how building local networks of R users may be more important in this effort than top-down, technological solutions. Our survey does show that personal recommendations have been important for many individuals in evaluating R packages. This is yet another area where local user groups can continue to have important impact. Some ways to share this experience more broadly would be online video series or live data analysis, such as those by Sean Taylor and Roger Peng.
CRAN Task Views
Some participants wondered whether the idea of a CRAN Task View is outdated in the current climate with so many packages, and whether it is even possible for one person to main one effectively. Others responded that CTVs are all about curation, which is still important, perhaps even more important now. We had at least one CTV maintainer present in our breakout session, and several things were presented as important in order for CTV maintainers to do their jobs:
- Package maintainers should update their
NEWSfiles. - Package maintainers need to write good documentation.
These are helpful for all R users, of course, but also for maintainers of CRAN Task Views. The pkgdown package was mentioned as a great way to make documentation visible.
CRAN and You
Participants had several ideas about how things are done on CRAN now and adjustments that might be made in the interest of discovering and evaluating packages. One idea that came up several times was the possibility of keywords or tagging for packages. I have since learned that there is support for some tagging architecture for packages on CRAN (for example, see here) in the DESCRIPTION file using ACM, JEL, or MSC classifications. These are fairly unwieldy lists currently and something like an RStudio addin could be used to navigate them, if they were widely used.
Another desire participants voiced was for more information directly on CRAN, such as the number of downloads for packages. Participants also suggested that vignettes for context-specific tasks like the Bioconductor Workflows would be helpful for package discovery and evaluation, either associated with CRAN or perhaps the R Journal. Finally, there was some discussion about whether the very minimal gate-keeping on CRAN was good or bad for the community, although the general feeling was that efforts to keep packages off CRAN would not be positive.
More data, more problems
Some of the package developers at the session wondered why, when R is a data-centric language, developers have such primitive analytics about their users. Issues of user privacy are central here, but there might be opt-in options that could help both package developers and users make better decisions. The idea of a recommender system for R packages was brought up multiple times, perhaps a Tinder for R packages like papr, the Tinder for academic preprints. Both the users and developers present thought that data on package use (instead of package downloads alone) would be helpful in evaluating how important or helpful R packages are. Participants also discussed the possibility of a linter for analysis scripts, similar in concept to linters for code, that would suggest packages and good practice. Such a linter would necessarily be opinionated, but almost all of the efforts to suggest and evaluate R packages are at some level.
Moving forward
You can look to hear more from my collaborators on this session soon. I am really happy that this discussion is happening in our community. One thing that I am taking from it is increased respect and value for the work done by local meetup group organizers and individuals who contribute to spreading the R love, both online and in their communities. Turns out that is how people learn! Something else I am moving forward with is a continued commitment to growing my skills as a package developer. Writing good documentation and adopting best practices makes this whole challenge better for everyone, from the CRAN Task View maintainer to the new R user. I am very happy to hear feedback or questions from you!