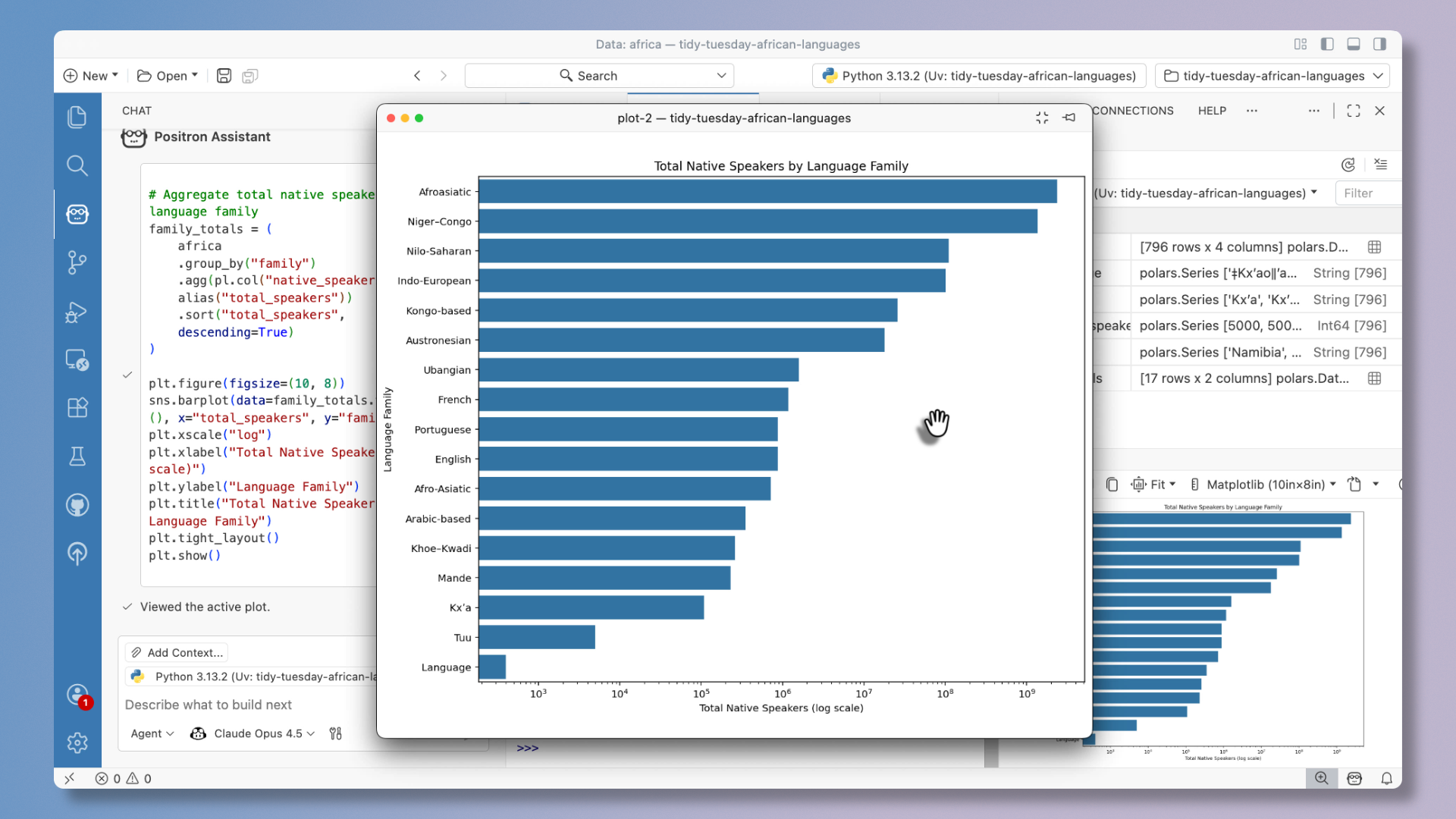
Use Positron Assistant with GitHub Copilot
The newest monthly release of Positron has a revamp of the integration between GitHub Copilot and Positron Assistant.
Machine learning, text analysis, and more
The newest monthly release of Positron has a revamp of the integration between GitHub Copilot and Positron Assistant.
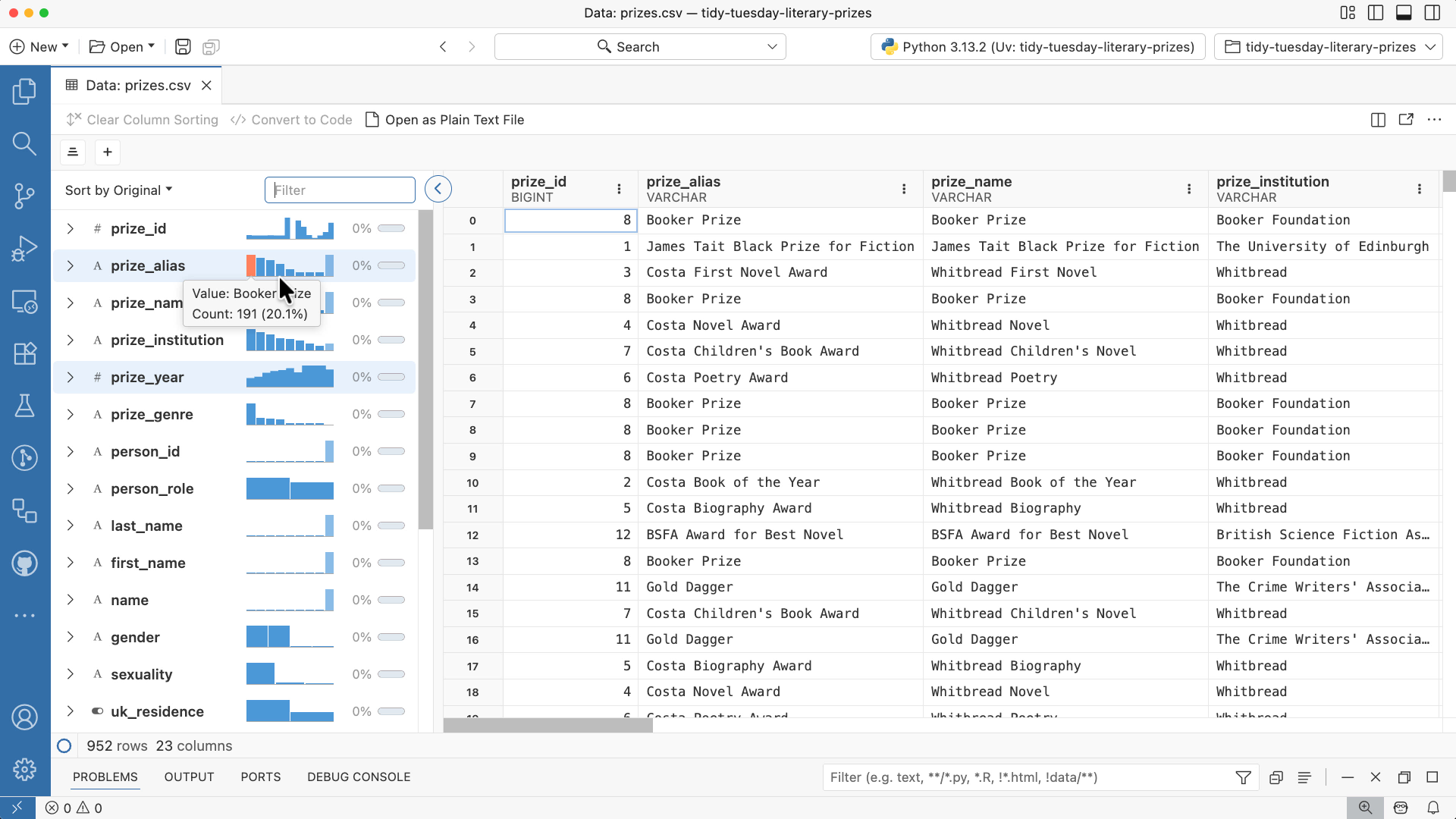
The newest monthly release of Positron delivers some fresh new features for the Data Explorer.
See how you can use Positron, a new, next-generation data science IDE, for R package development tasks and releasing a new version of an R package.
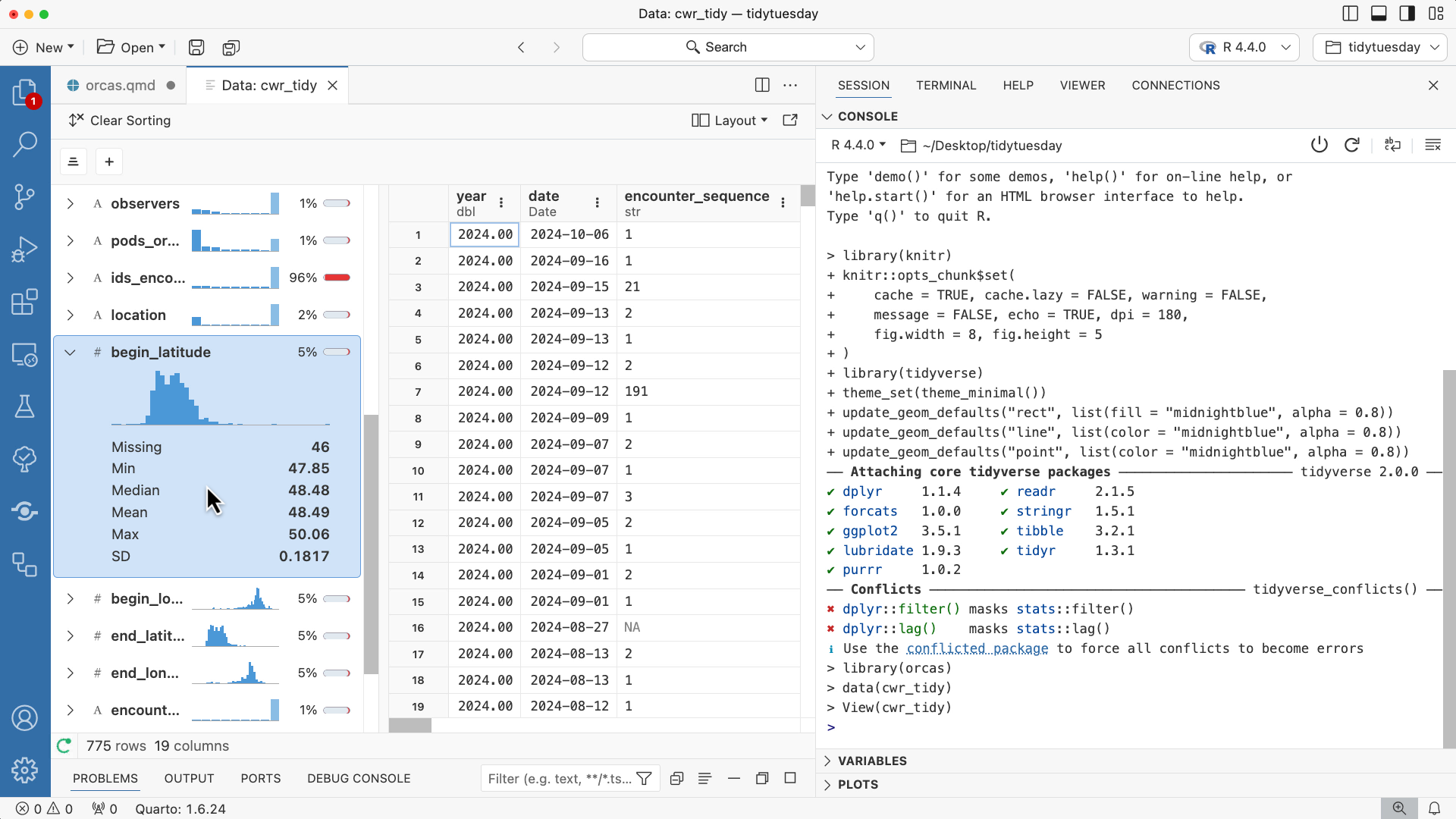
Get to know Positron, a new, next-generation data science IDE, using this week’s Tidy Tuesday data on encounters with orcas.
Let’s walk through the ML lifecycle from EDA to model development to deployment, using tidymodels, vetiver, and Posit Team.