Fixing your mistakes: sentiment analysis edition
By Julia Silge
June 14, 2019
Today tidytext 0.2.1 is available on CRAN! This new release of tidytext has a collection of nice new features.
- Bug squashing! 🐛
- Improvements to error messages and documentation 📃
- Switching from broom to generics for lighter dependencies
- Addition of some helper plotting functions I look forward to blogging about soon
An additional change is significant and may be felt by you, the user, so I want to share a bit about it.
Once upon a time
When we started building tidytext back in 2016, one of the very first things we did was add sentiment lexicons as datasets within the R package itself. We used the knowledge we had at the time and followed the practices we saw other OSS packages for text analysis following. However, it turns out that this was not the right approach from a licensing standpoint, because the lexicon licenses were not the same as the package’s license. I’m sure you can imagine that this is not a great thing to come to grips with after several years and half a million downloads! 😩
Making it right
The next step for me was to contact the creators of the sentiment lexicons we had included, let them know how we had handled their work, and see how they wanted to move forward. I was so pleased with the gracious responses I got back, both from the creators who gave permission to keep their work in an OSS package and those who said, “No thank you.” These creators were uniformly appreciative and helpful, and I want to thank them for being so gracious with me through this process of unwinding earlier mistakes.
Fortunately, there was an option already in the works for keeping most of these datasets easily available to R users, although not directly as a dataset in an R package. Emil Hvitfeldt had been working on a new package textdata that downloads, parses, stores, and loads text datasets. Emil’s package also just got on CRAN this week, and tidytext now uses textdata to access sentiment lexicons that are not stored directly in it.
How does textdata work? The first time you use one of the functions for accessing an included text dataset, such as lexicon_afinn() or dataset_sentence_polarity(), the function will prompt you to agree that you understand the dataset’s license or terms of use and then download the dataset to your computer.
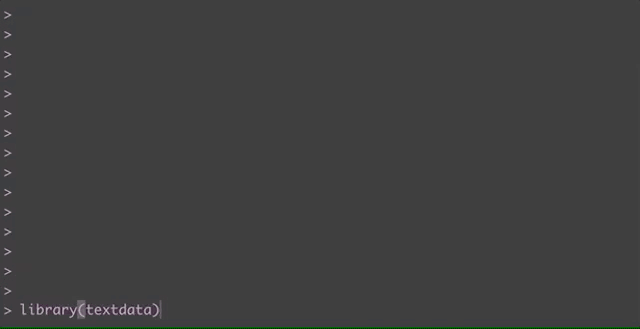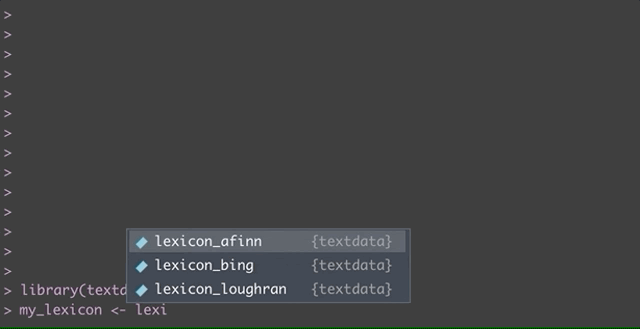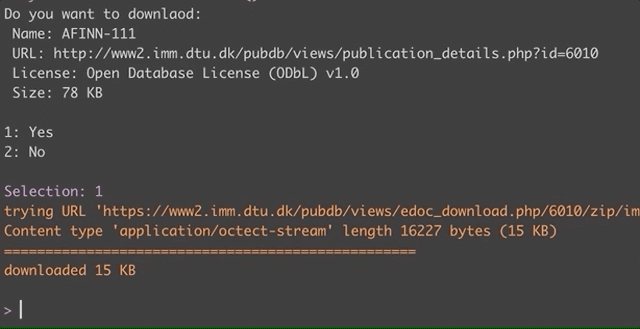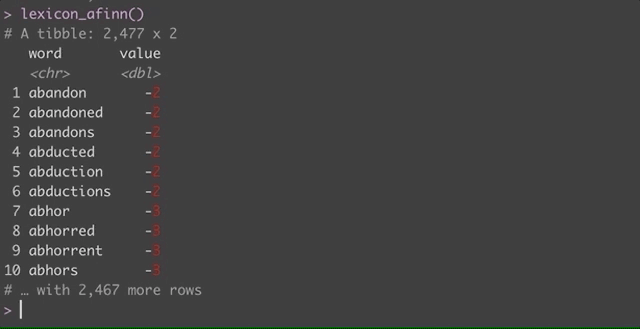
After the first use, each time you use a function like lexicon_afinn(), the function will load the dataset from disk. The function tidytext::get_sentiments() now calls the appropriate function from textdata, for lexicons not stored within tidytext itself.
Where are we now?
So, where does that leave us?
- The sentiment lexicon of Bing Liu and collaborators is still a dataset within tidytext, as he has explicitly given permission for us to include it there. If you need a sentiment lexicon to use in another R package, this is the easiest one to use.
- The AFINN lexicon is available through textdata, under an OSS license different from tidytext’s license.
- The sentiment lexicon of Loughran and McDonald for financial documents is available through textdata for research purposes, but you must obtain a license from the creators for commercial use.
- The NRC lexicon is currently not available through any package I am involved in.
I believe I have contacted all the R package maintainers who are impacted by these changes, but let me know if I missed you! I would love to help out if I can. I am still unwinding a few more necessary changes to other impacted work, so look for more updates soon.
I want to send a huge thanks to Emil for his quick work and collaboration on getting the textdata package finished and submitted so quickly, and to the lexicon creators for the way they have responded to this situation. Dealing with your own mistakes is challenging, but I am glad to be moving forward from a better place.