Term Frequency and tf-idf Using Tidy Data Principles
By Julia Silge
June 27, 2016
At the end of last week, Dave Robinson and I released a new version of tidytext on CRAN, our R package for text mining using tidy data principles. You can check out my first blog post about tidytext to learn a bit about the philosophy of the package and see some of the ways to use it, or see the package on GitHub. In this new release (tidytext 0.1.1), we have added more documentation, fixed some bugs, developed better testing/CI, and added some new functionality. One of the things I am most excited about is an implementation of tf-idf using a tidy data framework; learning about and using tf-idf has been one of my goals recently and I am so happy with the work we’ve done.
A central question in text mining and natural language processing is how to quantify what a document is about. Can we do this by looking at the words that make up the document? One way to approach how important a word can be is its term frequency (tf), how frequently a word occurs in a document. There are words in a document, though, that occur many times but may not be important; in English, these are probably words like “the”, “is”, “of”, and so forth. You might take the approach of adding words like these to a list of stop words and removing them before analysis, but it is possible that some of these words might be more important in some documents than others. A list of stop words is not a sophisticated approach to adjusting term frequency for commonly used words.
Another approach is to look at a term’s inverse document frequency (idf), which decreases the weight for commonly used words and increases the weight for words that are not used very much in a collection of documents. This can be combined with term frequency to calculate a term’s tf-idf, the frequency of a term adjusted for how rarely it is used. It is intended to measure how important a word is to a document in a collection (or corpus) of documents. It is a rule-of-thumb or heuristic quantity; while it has proved useful in text mining, search engines, etc., its theoretical foundations are considered less than firm by information theory experts. The inverse document frequency for any given term is defined as
\[idf(\text{term}) = \ln{\left(\frac{n_{\text{documents}}}{n_{\text{documents containing term}}}\right)}\]
We can use tidy data principles to approach tf-idf analysis and use consistent, effective tools to quantify how important various terms are in a document that is part of a collection.
Jane Austen Again (YES, AGAIN)
Let’s start by looking at the published novels of Jane Austen and examine first term frequency, then tf-idf. We can start just by using dplyr verbs such as group_by and join. What are the most commonly used words in Jane Austen’s novels? (Let’s also calculate the total words in each novel here, for later use.)
library(dplyr)
library(janeaustenr)
library(tidytext)
book_words <- austen_books() %>%
unnest_tokens(word, text) %>%
count(book, word, sort = TRUE) %>%
ungroup()
total_words <- book_words %>% group_by(book) %>% summarize(total = sum(n))
book_words <- left_join(book_words, total_words)
book_words## # A tibble: 40,379 x 4
## book word n total
## <fctr> <chr> <int> <int>
## 1 Mansfield Park the 6206 160460
## 2 Mansfield Park to 5475 160460
## 3 Mansfield Park and 5438 160460
## 4 Emma to 5239 160996
## 5 Emma the 5201 160996
## 6 Emma and 4896 160996
## 7 Mansfield Park of 4778 160460
## 8 Pride & Prejudice the 4331 122204
## 9 Emma of 4291 160996
## 10 Pride & Prejudice to 4162 122204
## # ... with 40,369 more rowsThe usual suspects are here, “the”, “and”, “to”, and so forth. Let’s look at the distribution of n/total for each novel, the number of times a word appears in a novel divided by the total number of terms (words) in that novel. This is exactly what term frequency is.
library(ggplot2)
library(viridis)
ggplot(book_words, aes(n/total, fill = book)) +
geom_histogram(alpha = 0.8, show.legend = FALSE) +
xlim(NA, 0.0009) +
labs(title = "Term Frequency Distribution in Jane Austen's Novels",
y = "Count") +
facet_wrap(~book, ncol = 2, scales = "free_y") +
theme_minimal(base_size = 13) +
scale_fill_viridis(end = 0.85, discrete=TRUE) +
theme(strip.text=element_text(hjust=0)) +
theme(strip.text = element_text(face = "italic"))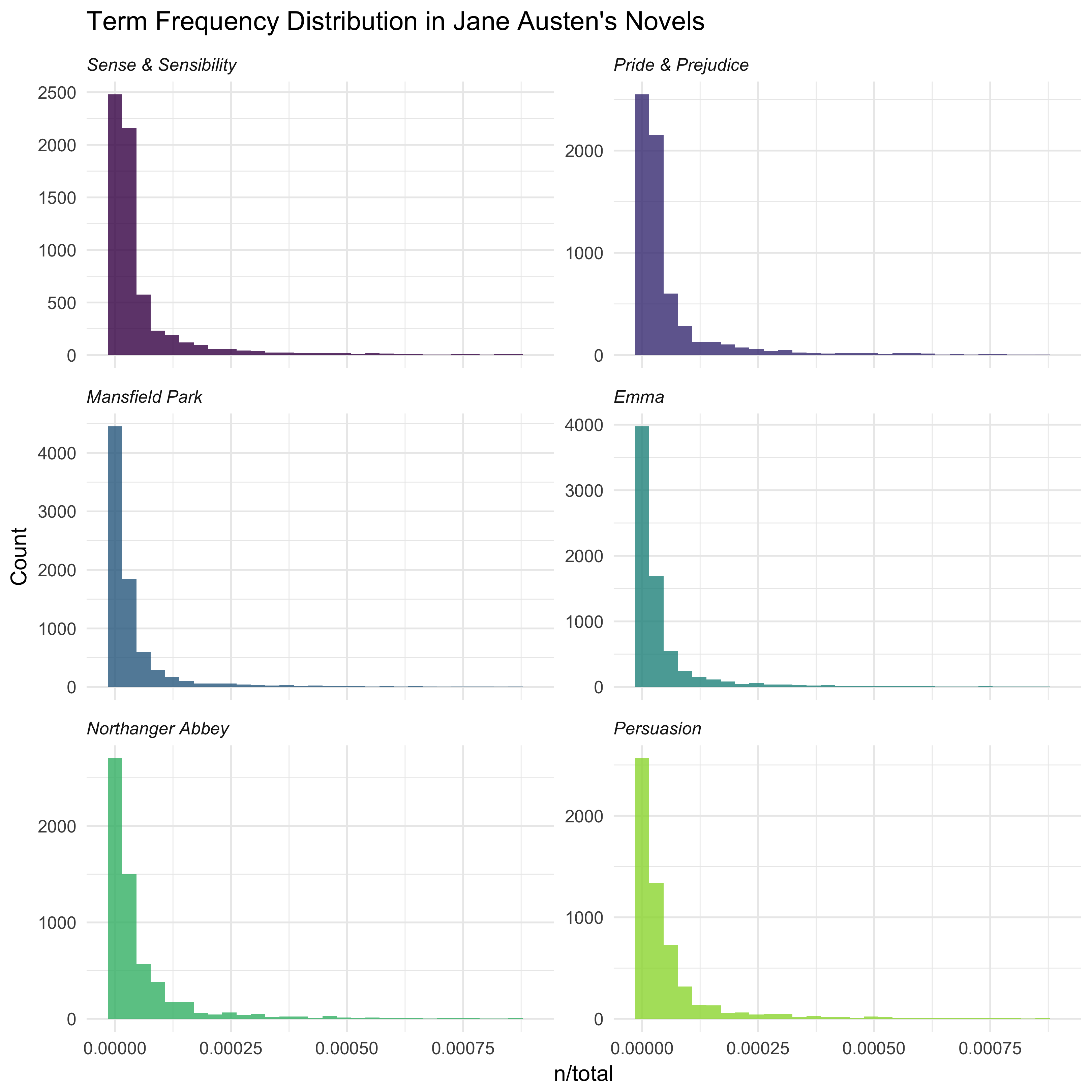
There are very long tails to the right for these novels (those extremely common words!) that I have not shown in these plots. These plots exhibit similar distributions for all the novels, with many words that occur rarely and fewer words that occur frequently. The idea of tf-idf is to find the important words for the content of each document by decreasing the weight for commonly used words and increasing the weight for words that are not used very much in a collection or corpus of documents, in this case, the group of Jane Austen’s novels as a whole. Calculating tf-idf attempts to find the words that are important (i.e., common) in a text, but not too common. Let’s do that now.
book_words <- book_words %>%
bind_tf_idf(word, book, n)
book_words## # A tibble: 40,379 x 7
## book word n total tf idf tf_idf
## <fctr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 Mansfield Park the 6206 160460 0.03867631 0 0
## 2 Mansfield Park to 5475 160460 0.03412065 0 0
## 3 Mansfield Park and 5438 160460 0.03389007 0 0
## 4 Emma to 5239 160996 0.03254118 0 0
## 5 Emma the 5201 160996 0.03230515 0 0
## 6 Emma and 4896 160996 0.03041069 0 0
## 7 Mansfield Park of 4778 160460 0.02977689 0 0
## 8 Pride & Prejudice the 4331 122204 0.03544074 0 0
## 9 Emma of 4291 160996 0.02665284 0 0
## 10 Pride & Prejudice to 4162 122204 0.03405780 0 0
## # ... with 40,369 more rowsNotice that idf and thus tf-idf are zero for these extremely common words. These are all words that appear in all six of Jane Austen’s novels, so the idf term (which will then be the natural log of 1) is zero. The inverse document frequency (and thus tf-idf) is very low (near zero) for words that occur in many of the documents in a collection; this is how this approach decreases the weight for common words. The inverse document frequency will be a higher number for words that occur in fewer of the documents in the collection. Let’s look at terms with high tf-idf in Jane Austen’s works.
book_words %>%
select(-total) %>%
arrange(desc(tf_idf)) ## # A tibble: 40,379 x 6
## book word n tf idf tf_idf
## <fctr> <chr> <int> <dbl> <dbl> <dbl>
## 1 Sense & Sensibility elinor 623 0.005193528 1.791759 0.009305552
## 2 Sense & Sensibility marianne 492 0.004101470 1.791759 0.007348847
## 3 Mansfield Park crawford 493 0.003072417 1.791759 0.005505032
## 4 Pride & Prejudice darcy 373 0.003052273 1.791759 0.005468939
## 5 Persuasion elliot 254 0.003036207 1.791759 0.005440153
## 6 Emma emma 786 0.004882109 1.098612 0.005363545
## 7 Northanger Abbey tilney 196 0.002519928 1.791759 0.004515105
## 8 Emma weston 389 0.002416209 1.791759 0.004329266
## 9 Pride & Prejudice bennet 294 0.002405813 1.791759 0.004310639
## 10 Persuasion wentworth 191 0.002283132 1.791759 0.004090824
## # ... with 40,369 more rowsHere we see all proper nouns, names that are in fact important in these novels. None of them occur in all of novels, and they are important, characteristic words for each text. Some of the values for idf are the same for different terms because there are 6 documents in this corpus and we are seeing the numerical value for ln(6/1), ln(6/2), etc. Let’s look at a visualization for these high tf-idf words.
library(ggstance)
library(ggthemes)
plot_austen <- book_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word))))
ggplot(plot_austen[1:20,], aes(tf_idf, word, fill = book, alpha = tf_idf)) +
geom_barh(stat = "identity") +
labs(title = "Highest tf-idf words in Jane Austen's Novels",
y = NULL, x = "tf-idf") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_alpha_continuous(range = c(0.6, 1), guide = FALSE) +
scale_x_continuous(expand=c(0,0)) +
scale_fill_viridis(end = 0.85, discrete=TRUE) +
theme(legend.title=element_blank()) +
theme(legend.justification=c(1,0), legend.position=c(1,0))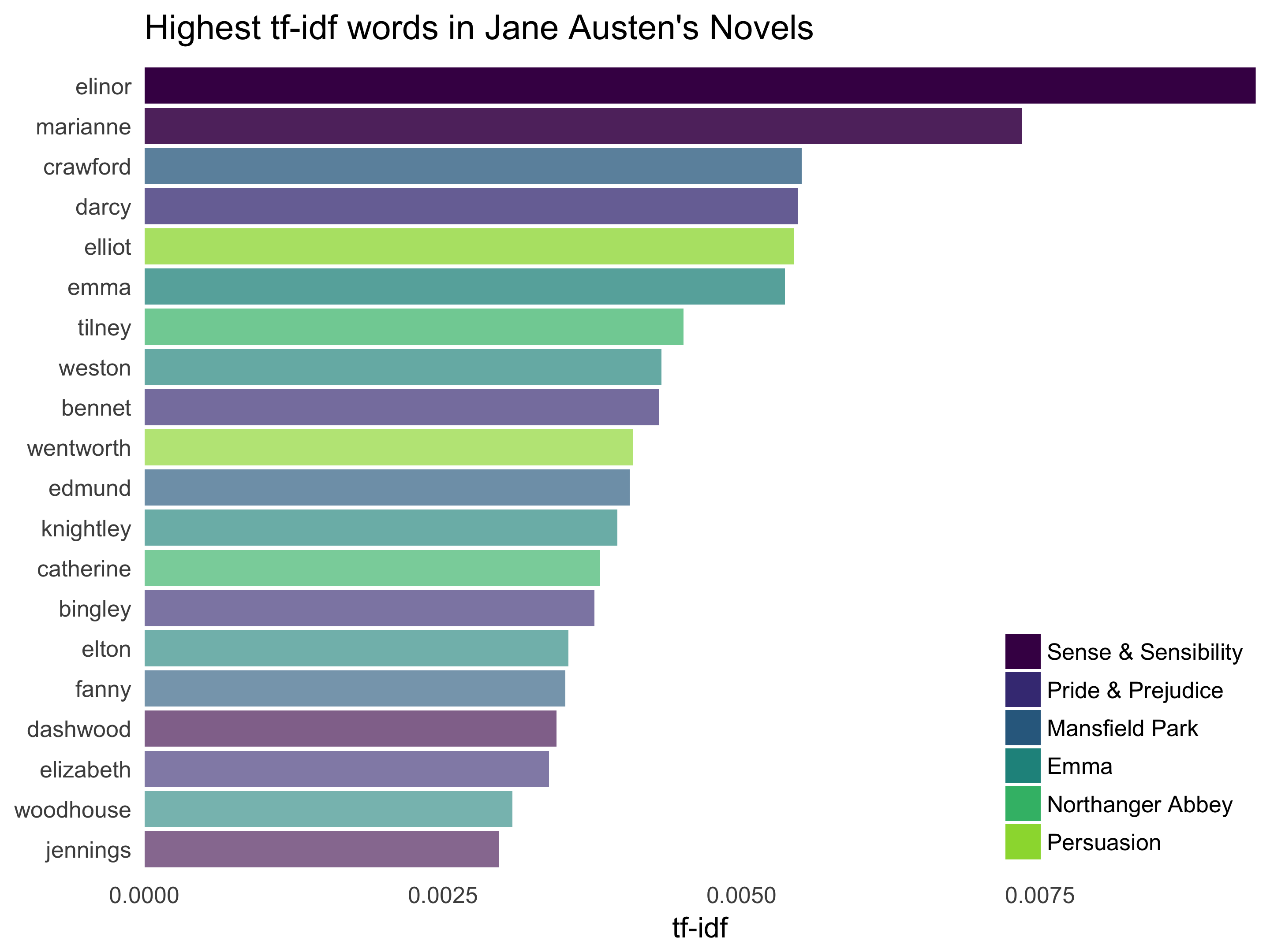
Let’s look at the novels individually.
plot_austen <- plot_austen %>% group_by(book) %>% top_n(15) %>% ungroup
ggplot(plot_austen, aes(tf_idf, word, fill = book, alpha = tf_idf)) +
geom_barh(stat = "identity", show.legend = FALSE) +
labs(title = "Highest tf-idf words in Jane Austen's Novels",
y = NULL, x = "tf-idf") +
facet_wrap(~book, ncol = 2, scales = "free") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_alpha_continuous(range = c(0.6, 1)) +
scale_x_continuous(expand=c(0,0)) +
scale_fill_viridis(end = 0.85, discrete=TRUE) +
theme(strip.text=element_text(hjust=0)) +
theme(strip.text = element_text(face = "italic"))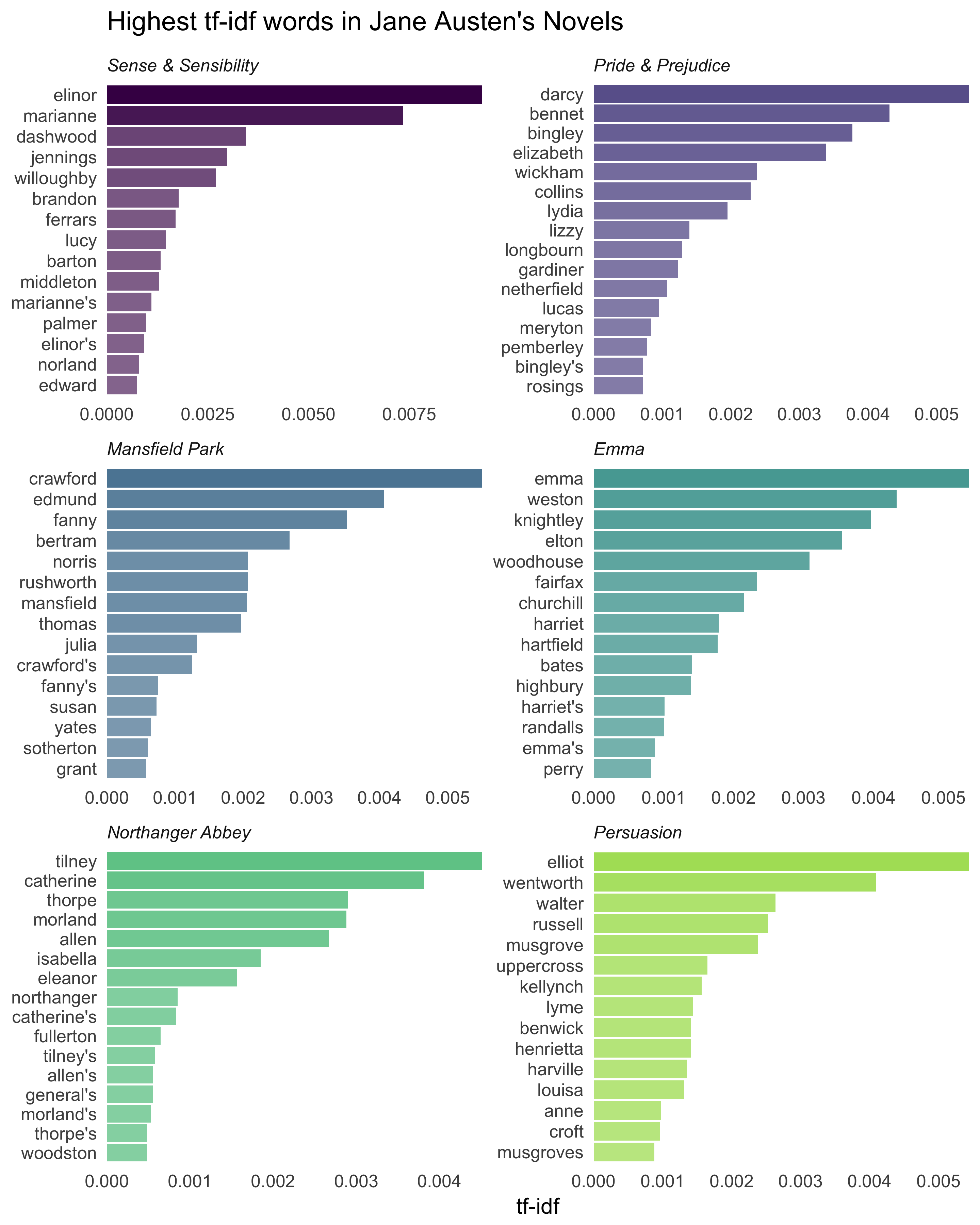
Still all proper nouns! These words are, as measured by tf-idf, the most important to each novel and most readers would likely agree.
A Different Corpus
Let’s work with another corpus of documents, to see what terms are important in a different set of works. In fact, let’s leave the world of fiction and narrative entirely. My background is in physics, so let’s download some classic physics texts from Project Gutenberg and see what terms are important in these works, as measured by tf-idf. Let’s download Discourse on Floating Bodies by Galileo Galilei, Treatise on Light by Christiaan Huygens, Experiments with Alternate Currents of High Potential and High Frequency by Nikola Tesla, and Relativity: The Special and General Theory by Albert Einstein.
This is a pretty diverse bunch. They may all be physics classics, but they were written across a 300-year timespan, and some of them were first written in other languages and then translated to English. Perfectly homogeneous these are not, but that doesn’t stop this from being an interesting exercise!
library(gutenbergr)
physics <- gutenberg_download(c(37729, 14725, 13476, 5001),
meta_fields = "author")
physics_words <- physics %>%
unnest_tokens(word, text) %>%
count(author, word, sort = TRUE) %>%
ungroup()
physics_words## # A tibble: 12,592 x 3
## author word n
## <chr> <chr> <int>
## 1 Galilei, Galileo the 3760
## 2 Tesla, Nikola the 3604
## 3 Huygens, Christiaan the 3553
## 4 Einstein, Albert the 2994
## 5 Galilei, Galileo of 2049
## 6 Einstein, Albert of 2030
## 7 Tesla, Nikola of 1737
## 8 Huygens, Christiaan of 1708
## 9 Huygens, Christiaan to 1207
## 10 Tesla, Nikola a 1176
## # ... with 12,582 more rowsHere we see just the raw counts, and of course these documents are all very different lengths. Let’s go ahead and calculate tf-idf.
physics_words <- physics_words %>%
bind_tf_idf(word, author, n)
plot_physics <- physics_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
mutate(author = factor(author, levels = c("Galilei, Galileo",
"Huygens, Christiaan",
"Tesla, Nikola",
"Einstein, Albert")))
ggplot(plot_physics[1:20,], aes(tf_idf, word, fill = author, alpha = tf_idf)) +
geom_barh(stat = "identity") +
labs(title = "Highest tf-idf words in Classic Physics Texts",
y = NULL, x = "tf-idf") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_alpha_continuous(range = c(0.6, 1), guide = FALSE) +
scale_x_continuous(expand=c(0,0)) +
scale_fill_viridis(end = 0.6, discrete=TRUE) +
theme(legend.title=element_blank()) +
theme(legend.justification=c(1,0), legend.position=c(1,0))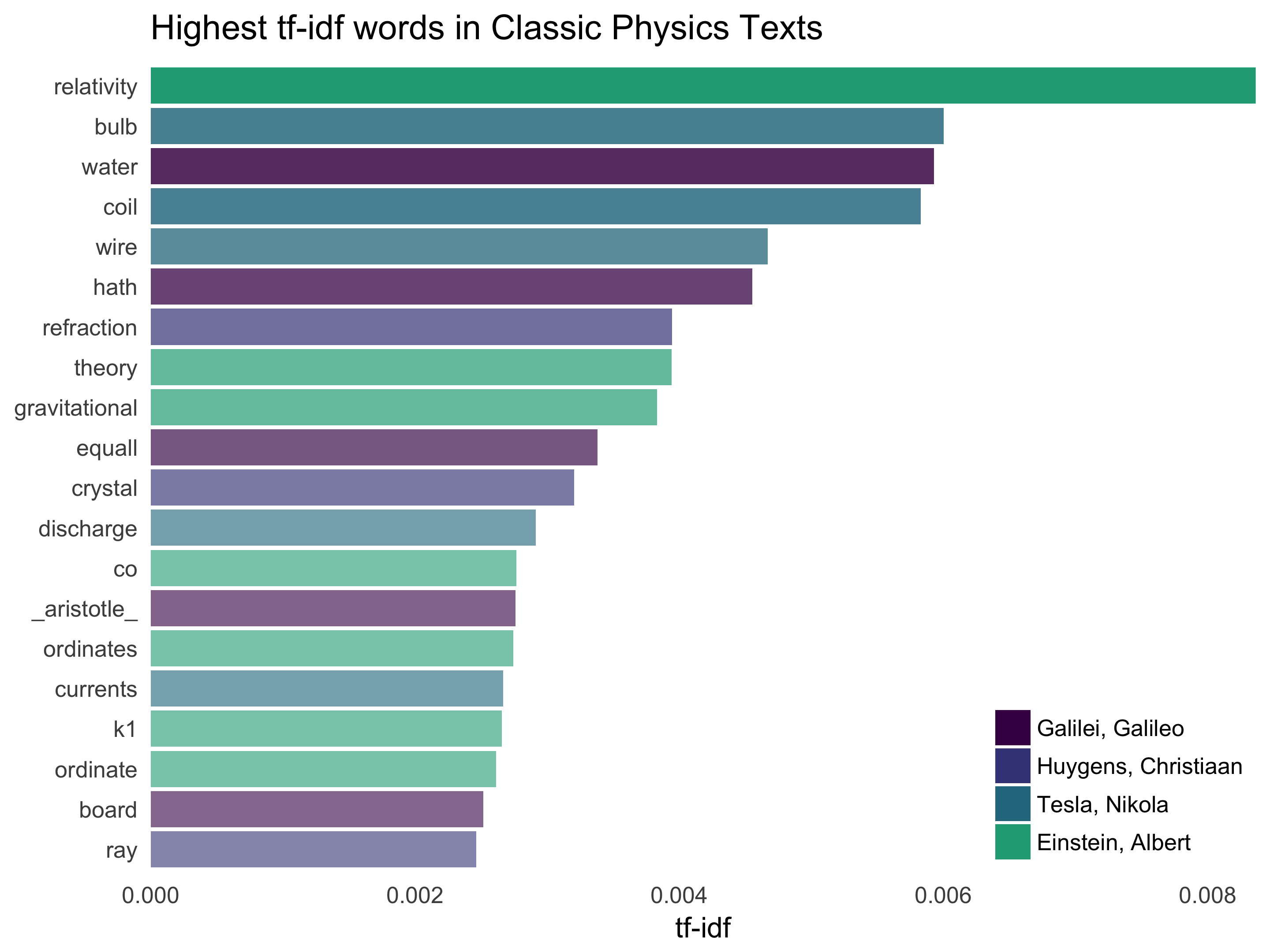
Nice! Let’s look at each text individually.
plot_physics <- plot_physics %>% group_by(author) %>%
top_n(15, tf_idf) %>%
mutate(word = reorder(word, tf_idf))
ggplot(plot_physics, aes(tf_idf, word, fill = author, alpha = tf_idf)) +
geom_barh(stat = "identity", show.legend = FALSE) +
labs(title = "Highest tf-idf words in Classic Physics Texts",
y = NULL, x = "tf-idf") +
facet_wrap(~author, ncol = 2, scales = "free") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_alpha_continuous(range = c(0.6, 1)) +
scale_x_continuous(expand=c(0,0)) +
scale_fill_viridis(end = 0.6, discrete=TRUE) +
theme(strip.text=element_text(hjust=0))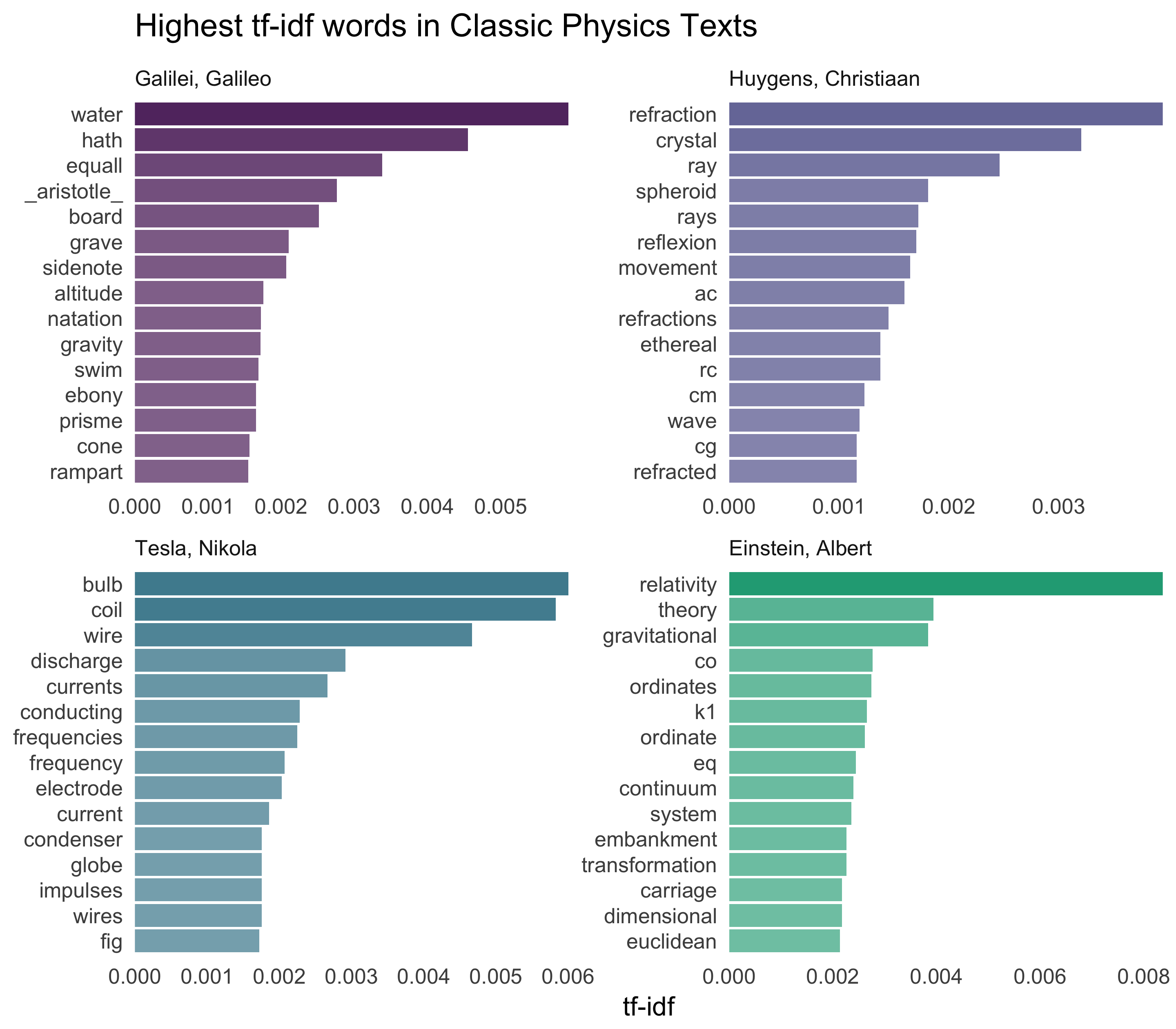
Very interesting indeed. One thing I saw here that I wanted to understand was what was going on with “gif” in the Einstein text?!
grep("gif", physics$text, value = TRUE)[1:10]## [1] " Fig. 01: file fig01.gif"
## [2] " eq. 1: file eq01.gif"
## [3] " eq. 2: file eq02.gif"
## [4] " eq. 3: file eq03.gif"
## [5] " eq. 4: file eq04.gif"
## [6] " eq. 05a: file eq05a.gif"
## [7] " eq. 05b: file eq05b.gif"
## [8] " eq. 07: file eq07.gif"
## [9] " eq. 08: file eq08.gif"
## [10] " eq. 09: file eq09.gif"Some cleaning up of the text might be in order. The same thing is true for “eq”, obviously here. “K1” is the name of a coordinate system for Einstein:
grep("K1", physics$text, value = TRUE)[1]## [1] "to a second co-ordinate system K1 provided that the latter is"Also notice that in this line we have “co-ordinate”, which explains why there are separate “co” and “ordinate” items in the high tf-idf words for the Einstein text. “AB”, “RC”, and so forth are names of rays, circles, angles, and so forth for Huygens.
grep("AK", physics$text, value = TRUE)[1]## [1] "Now let us assume that the ray has come from A to C along AK, KC; the"Let’s remove some of these less meaningful words to make a better plot to end on.
mystopwords <- data_frame(word = c("gif", "eq", "co", "rc", "ac", "ak", "bn",
"fig", "file", "cg", "cb"))
physics_words <- anti_join(physics_words, mystopwords, by = "word")
plot_physics <- physics_words %>%
arrange(desc(tf_idf)) %>%
mutate(word = factor(word, levels = rev(unique(word)))) %>%
group_by(author) %>%
top_n(15, tf_idf) %>%
ungroup %>%
mutate(author = factor(author, levels = c("Galilei, Galileo",
"Huygens, Christiaan",
"Tesla, Nikola",
"Einstein, Albert")))
ggplot(plot_physics, aes(tf_idf, word, fill = author, alpha = tf_idf)) +
geom_barh(stat = "identity", show.legend = FALSE) +
labs(title = "Highest tf-idf words in Classic Physics Texts",
y = NULL, x = "tf-idf") +
facet_wrap(~author, ncol = 2, scales = "free") +
theme_tufte(base_family = "Arial", base_size = 13, ticks = FALSE) +
scale_alpha_continuous(range = c(0.6, 1)) +
scale_x_continuous(expand=c(0,0)) +
scale_fill_viridis(end = 0.6, discrete=TRUE) +
theme(strip.text=element_text(hjust=0))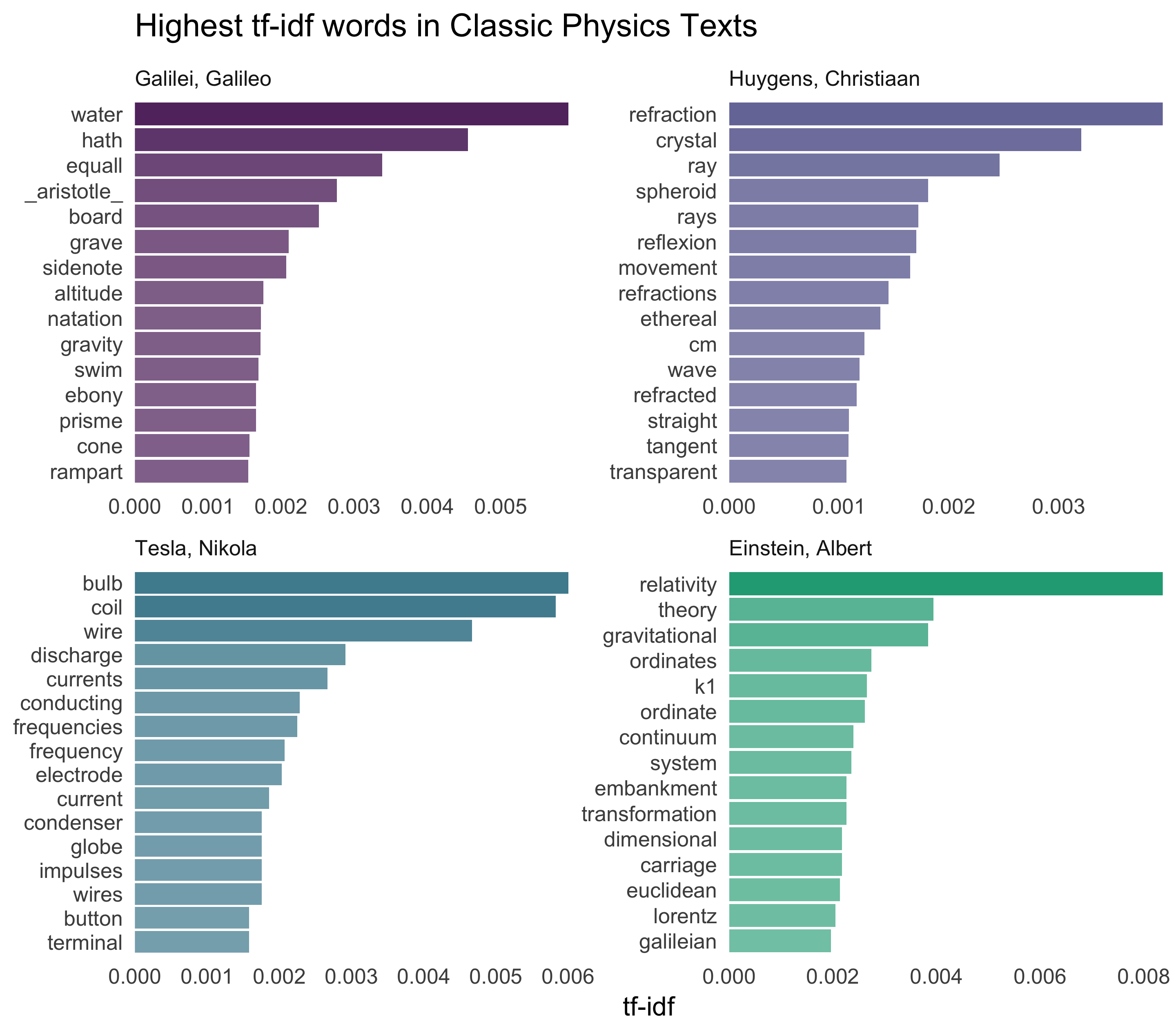
I feel like we don’t hear enough about ramparts or things being ethereal in physics today.
The End
Other notable new functionality in tidytext 0.1.1 includes the ability to tidy LDA objects and approach topic modeling using tidy data principles; check out the topic modeling vignette that is included in the new release for a sad tale of a vandal breaking into a library and tearing apart books. The R Markdown file used to make this blog post is available here. I am very happy to hear feedback or questions!