Tidy Text Mining with R
By Julia Silge
October 28, 2016
I am so pleased to announce that tidytext 0.1.2 is now available on CRAN. This release of tidytext, a package for text mining using tidy data principles by Dave Robinson and me, includes some bug fixes and performance improvements, as well as some new functionality.
There is now a handy function for accessing the various lexicons in the sentiments dataset without the columns that are not used in that particular dataset; this makes these datasets even easier to use with pipes and joins from dplyr.
library(tidytext)
library(dplyr)
get_sentiments("afinn")## # A tibble: 2,476 x 2
## word score
## <chr> <int>
## 1 abandon -2
## 2 abandoned -2
## 3 abandons -2
## 4 abducted -2
## 5 abduction -2
## 6 abductions -2
## 7 abhor -3
## 8 abhorred -3
## 9 abhorrent -3
## 10 abhors -3
## # ... with 2,466 more rowsget_sentiments("nrc") %>%
filter(sentiment == "joy")## # A tibble: 689 x 2
## word sentiment
## <chr> <chr>
## 1 absolution joy
## 2 abundance joy
## 3 abundant joy
## 4 accolade joy
## 5 accompaniment joy
## 6 accomplish joy
## 7 accomplished joy
## 8 achieve joy
## 9 achievement joy
## 10 acrobat joy
## # ... with 679 more rowsThe unnest_tokens package can now process html, xml, latex or man pages (using the hunspell package).
library(readr)
data_frame(text = read_lines("https://en.wikipedia.org/wiki/Pride_and_Prejudice_and_Zombies")) %>%
unnest_tokens(word, text, format = "html")## # A tibble: 2,804 x 1
## word
## <chr>
## 1 pride
## 2 and
## 3 prejudice
## 4 and
## 5 zombies
## 6 wikipedia
## 7 pride
## 8 and
## 9 prejudice
## 10 and
## # ... with 2,794 more rowsThis only works for tokenizing by single words.
Since the last release of this package, we published a short paper on tidytext in the Journal of Open Source Software. Our experience with JOSS was great, and you can find the citation within R by typing citation("tidytext").
BUT WAIT THERE’S MORE
I am even more excited to publicly announce the book that Dave and I have been working on.
Dave and I have used the bookdown package by Yihui Xie to write and build our book on text mining using tidy data principles. Our goal in writing this book is to provide resources and examples for people who want to use tidy tools to approach natural language processing tasks. The intended audience for this book includes people (like us!) who don’t have extensive backgrounds in computational linguistics but who need or want to analyze unstructured, text-heavy data. Using tidy data principles can make text mining easier, more effective, and consistent with tools that are already being used widely by many data scientists and analysts.
The book is partly composed of material from blog posts by both of us, the package’s vignettes, and various tutorials we have put together. We think it will be helpful to have all this material in one place, organized in a cohesive way for both newcomers to using this package and other users who need to look something up.
The book also includes new material that we haven’t published elsewhere. One chapter is about analyzing our own Twitter archives. How have Dave and I used our Twitter accounts?
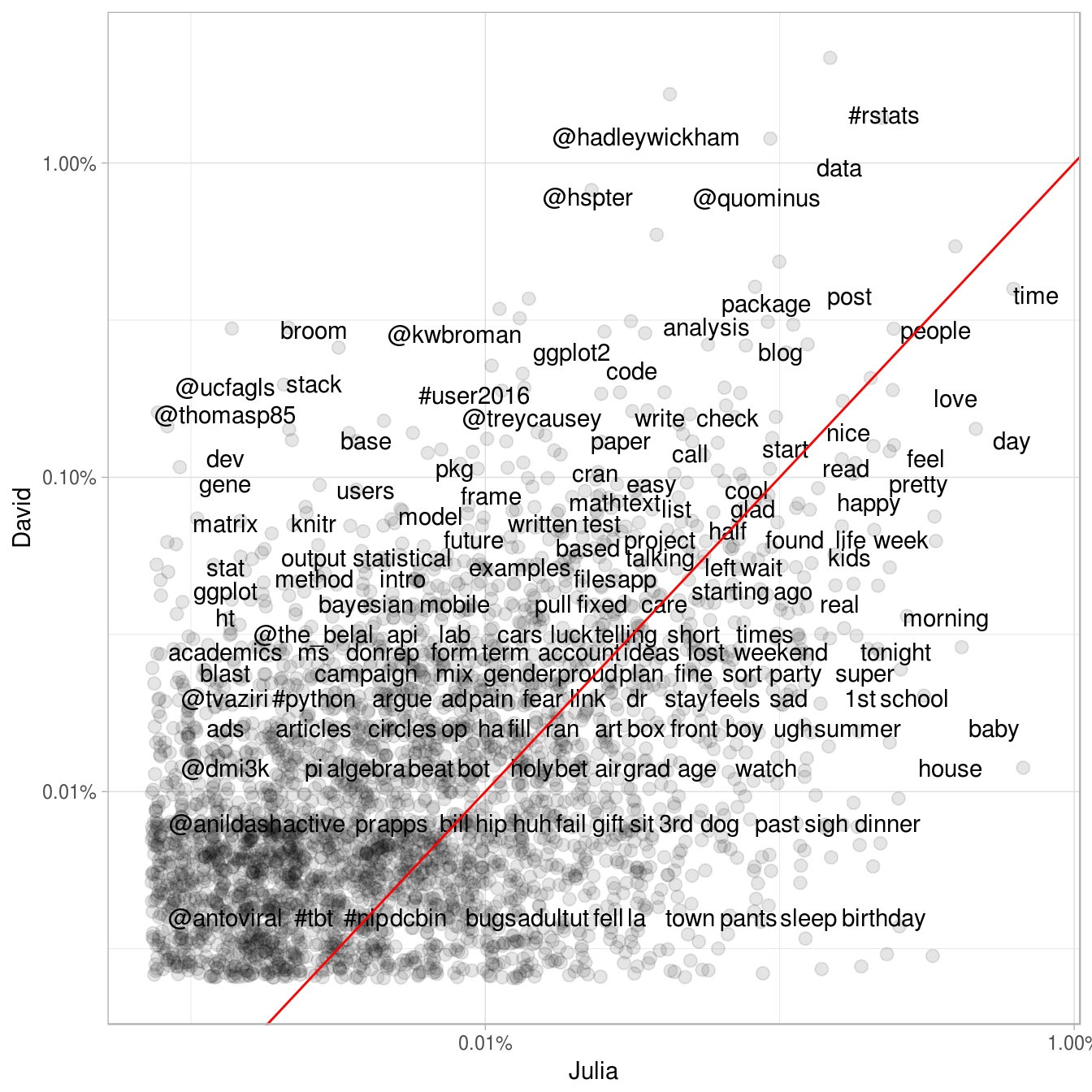
QUITE DIFFERENTLY, IT TURNS OUT.
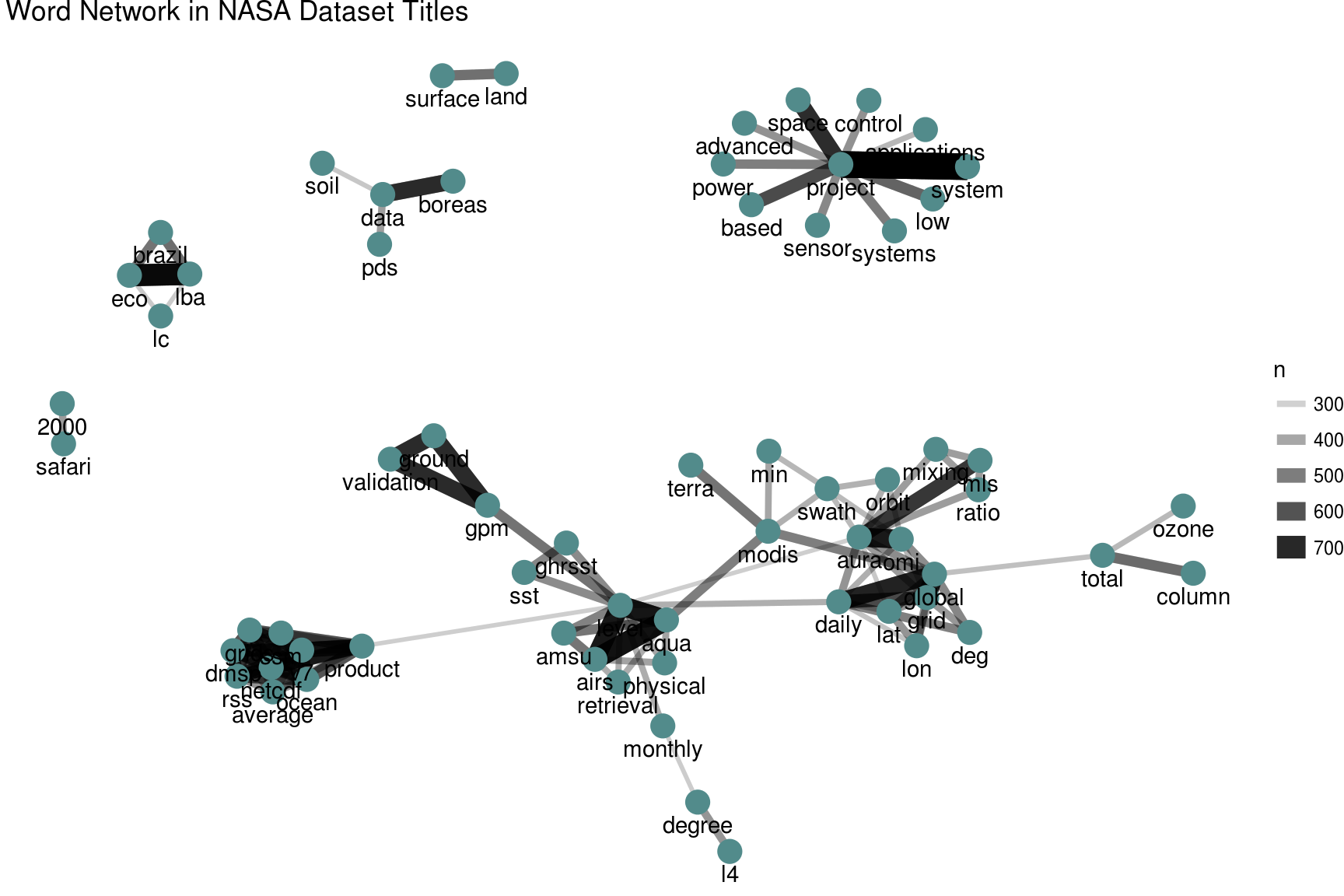
Another chapter that I am really excited about focuses on exploring NASA metadata. I am part of the NASA Datanauts class of 2016; it has been a great experience with lots of opportunities to meet interesting people and learn. The program is mostly oriented toward underrepresented groups in tech and is open to a variety of skill levels, including those who are true newcomers. I highly recommend applying for next year’s program if it might be a good fit for you! One of the projects I’ve worked on through this program is exploring NASA metadata. There are 32,000+ datasets at NASA, and we can use the metadata for these datasets to understand the connections between them. For just a sneak peek, here is a network of the most commonly co-occurring words in the titles of NASA datasets.
The End
Some of the later chapters are less developed currently than the earlier ones; Dave and I are still in the writing process and will be actively developing and honing the book in the near future. We are eager to share our work with the world at large, though, so go ahead and take a look! We plan to finish writing this book in the open, and we are open to suggestions and edits via the book’s GitHub repository. The R Markdown file used to make this blog post is available here. I am very happy to hear feedback or questions!