Tidy word vectors, take 2!
By Julia Silge
November 27, 2017
A few weeks ago, I wrote a post about finding word vectors using tidy data principles, based on an approach outlined by Chris Moody on the StitchFix tech blog. I’ve been pondering how to improve this approach, and whether it would be nice to wrap up some of these functions in a package, so here is an update!
Like in my previous post, let’s download half a million posts from the Hacker News corpus using the bigrquery package.
library(bigrquery)
library(tidyverse)
sql <- "#legacySQL
SELECT
stories.title AS title,
stories.text AS text
FROM
[bigquery-public-data:hacker_news.full] AS stories
WHERE
stories.deleted IS NULL
LIMIT
500000"
hacker_news_raw <- query_exec(sql, project = project, max_pages = Inf)And then let’s clean the text and make a data frame containing only the text, plus an ID to identify each “document”, i.e., post.
library(stringr)
hacker_news_text <- hacker_news_raw %>%
as_tibble() %>%
mutate(title = na_if(title, ""),
text = coalesce(title, text)) %>%
select(-title) %>%
mutate(text = str_replace_all(text, "'|"|/", "'"), ## weird encoding
text = str_replace_all(text, "<a(.*?)>", " "), ## links
text = str_replace_all(text, ">|<|&", " "), ## html yuck
text = str_replace_all(text, "&#[:digit:]+;", " "), ## html yuck
text = str_replace_all(text, "<[^>]*>", " "), ## mmmmm, more html yuck
postID = row_number())Sliding windows
Starting from here is where my approach has changed a bit. Instead of using the unnest_tokens() function a total of three times to find the skipgrams, here I only use unnest_tokens() once, and then use a function slide_windows() to identify the skipgram windows.
slide_windows <- function(tbl, doc_var, window_size) {
# each word gets a skipgram (window_size words) starting on the first
# e.g. skipgram 1 starts on word 1, skipgram 2 starts on word 2
each_total <- tbl %>%
group_by(!!doc_var) %>%
mutate(doc_total = n(),
each_total = pmin(doc_total, window_size, na.rm = TRUE)) %>%
pull(each_total)
rle_each <- rle(each_total)
counts <- rle_each[["lengths"]]
counts[rle_each$values != window_size] <- 1
# each word get a skipgram window, starting on the first
# account for documents shorter than window
id_counts <- rep(rle_each$values, counts)
window_id <- rep(seq_along(id_counts), id_counts)
# within each skipgram, there are window_size many offsets
indexer <- (seq_along(rle_each[["values"]]) - 1) %>%
map2(rle_each[["values"]] - 1,
~ seq.int(.x, .x + .y)) %>%
map2(counts, ~ rep(.x, .y)) %>%
flatten_int() +
window_id
tbl[indexer, ] %>%
bind_cols(data_frame(window_id)) %>%
group_by(window_id) %>%
filter(n_distinct(!!doc_var) == 1) %>%
ungroup
}This allows us to get to a tidy data frame with PMI values for each pair of words. This PMI value is what tells us whether words likely to occur together or unlikely to occur together. I also was smarter and put the filter() to remove very rare words before trying to identifying skipgrams. In this example, a word has to be used 20 times (overall, in the 500,000 posts) to be included.
library(tidytext)
library(widyr)
tidy_pmi <- hacker_news_text %>%
unnest_tokens(word, text) %>%
add_count(word) %>%
filter(n >= 20) %>%
select(-n) %>%
slide_windows(quo(postID), 8) %>%
pairwise_pmi(word, window_id)
tidy_pmi## # A tibble: 30,853,734 x 3
## item1 item2 pmi
## <chr> <chr> <dbl>
## 1 best the 0.732
## 2 part the 0.501
## 3 is the 0.0365
## 4 that the -0.145
## 5 since the -0.0260
## 6 it's the -0.364
## 7 not the -0.262
## 8 in the 0.184
## 9 any the -0.643
## 10 fonts the -0.140
## # ... with 30,853,724 more rowsThis was the part of the blog posts where I hoped to wow everyone with a dramatic speed improvement, but it is a more modest one. Based on my benchmarking, this approach is 10% faster than the approach of my previous blog post. Identifying all the skipgram windows is a pretty expensive process. If you want a real-world estimate, it takes my computer about 7 minutes to complete this step.
We can then find the word vectors from the PMI values using the new widely_svd() function in widyr. This is much faster compared to the other step.
tidy_word_vectors <- tidy_pmi %>%
widely_svd(item1, item2, pmi, nv = 256, maxit = 1000)Exploring results
So hooray! We have found word vectors again, a bit faster, with clearer and easier-to-understand code. I do argue that this is a real benefit of this approach; it’s based on counting, dividing, and matrix decomposition and is thus much easier to understand and implement than anything with a neural network. And the results?
nearest_synonyms <- function(df, token) {
df %>%
widely(~ . %*% (.[token, ]), sort = TRUE)(item1, dimension, value) %>%
select(-item2)
}
tidy_word_vectors %>%
nearest_synonyms("tokyo")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 tokyo 0.0197
## 2 hong 0.0145
## 3 london 0.0144
## 4 kong 0.0141
## 5 paris 0.0140
## 6 cities 0.0101
## 7 japan 0.0100
## 8 singapore 0.00952
## 9 los 0.00899
## 10 san 0.00860
## # ... with 27,257 more rowstidy_word_vectors %>%
nearest_synonyms("python")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 python 0.0533
## 2 ruby 0.0309
## 3 java 0.0250
## 4 php 0.0241
## 5 c 0.0229
## 6 perl 0.0222
## 7 javascript 0.0203
## 8 django 0.0202
## 9 libraries 0.0184
## 10 languages 0.0180
## # ... with 27,257 more rowstidy_word_vectors %>%
nearest_synonyms("bitcoin")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 bitcoin 0.0626
## 2 currency 0.0328
## 3 btc 0.0320
## 4 coins 0.0300
## 5 blockchain 0.0285
## 6 bitcoins 0.0258
## 7 mining 0.0252
## 8 transactions 0.0241
## 9 transaction 0.0235
## 10 currencies 0.0228
## # ... with 27,257 more rowstidy_word_vectors %>%
nearest_synonyms("women")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 women 0.0648
## 2 men 0.0508
## 3 male 0.0345
## 4 female 0.0319
## 5 gender 0.0274
## 6 sex 0.0256
## 7 woman 0.0241
## 8 sexual 0.0226
## 9 males 0.0197
## 10 girls 0.0195
## # ... with 27,257 more rowsI’m still learning about how word vectors are evaluated to be able to make some kind claim about how good word vectors like these are, for realistic datasets. One way that word vectors can be evaluated is by looking at how well the vectors perform on analogy tasks, like King - Man + Woman = Queen. What are some analogies we can find in this Hacker News corpus? Let’s write a little function that will find the answer to token1 - token2 + token 3 = ???.
analogy <- function(df, token1, token2, token3) {
df %>%
widely(~ . %*% (.[token1, ] - .[token2, ] + .[token3, ]), sort = TRUE)(item1, dimension, value) %>%
select(-item2)
}
## operating systems
tidy_word_vectors %>%
analogy("osx", "apple", "microsoft")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 windows 0.0357
## 2 microsoft 0.0281
## 3 ms 0.0245
## 4 visual 0.0195
## 5 linux 0.0188
## 6 studio 0.0178
## 7 net 0.0171
## 8 desktop 0.0164
## 9 xp 0.0163
## 10 office 0.0147
## # ... with 27,257 more rows## countries
tidy_word_vectors %>%
analogy("germany", "berlin", "paris")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 germany 0.0320
## 2 france 0.0231
## 3 europe 0.0213
## 4 paris 0.0212
## 5 uk 0.0200
## 6 london 0.0178
## 7 eu 0.0176
## 8 spain 0.0175
## 9 italy 0.0170
## 10 countries 0.0163
## # ... with 27,257 more rows## THOUGHT LEADERS
tidy_word_vectors %>%
analogy("gates", "windows", "tesla")## # A tibble: 27,267 x 2
## item1 value
## <chr> <dbl>
## 1 tesla 0.0419
## 2 gates 0.0364
## 3 musk 0.0348
## 4 elon 0.0335
## 5 steve 0.0247
## 6 electric 0.0234
## 7 car 0.0234
## 8 ford 0.0228
## 9 larry 0.0222
## 10 bill 0.0219
## # ... with 27,257 more rowsWell, those last two are not perfect as the answers I’d identify as best are near the top but below the input tokens. This happens when I have trained vectors using GloVe too, though.
Since we have done a singular value decomposition, we can use our word vectors to understand what principal components explain the most variation in the Hacker News corpus.
tidy_word_vectors %>%
filter(dimension <= 24) %>%
group_by(dimension) %>%
top_n(12, abs(value)) %>%
ungroup %>%
mutate(item1 = reorder(item1, value)) %>%
group_by(dimension, item1) %>%
arrange(desc(value)) %>%
ungroup %>%
mutate(item1 = factor(paste(item1, dimension, sep = "__"),
levels = rev(paste(item1, dimension, sep = "__"))),
dimension = factor(paste0("Dimension ", dimension),
levels = paste0("Dimension ", as.factor(1:24)))) %>%
ggplot(aes(item1, value, fill = dimension)) +
geom_col(show.legend = FALSE) +
facet_wrap(~dimension, scales = "free_y", ncol = 4) +
scale_x_discrete(labels = function(x) gsub("__.+$", "", x)) +
coord_flip() +
labs(x = NULL, y = "Value",
title = "First 24 principal components of the Hacker News corpus",
subtitle = "Top words contributing to the components that explain the most variation")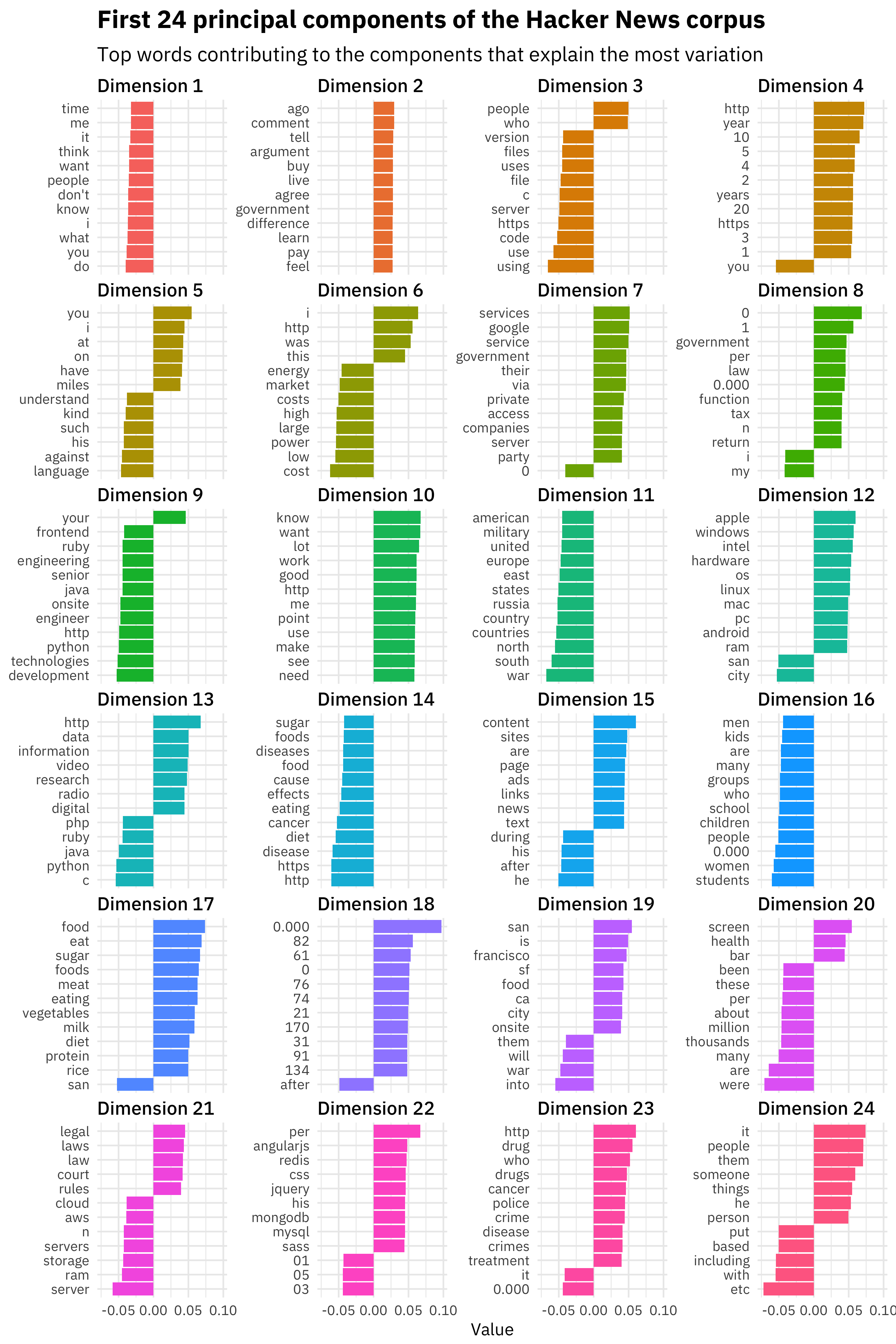
This is so great. The first two components contain mostly general purpose English words; remember that these are the vectors that explain the most variation in posts. Does a post contain a lot of these words or not? Then the third component and beyond start to contain more technical or topical words. Dimension 6 is about energy and markets, Dimension 11 is about geopolitics, Dimension 14 is about health discussions, Dimension 16 is about various kinds of people including kids/children/men/women/etc, and so on.
The End
I’m happy to have made a modest improvement in speed here, and to use some new functions from widyr that improve the intuition and understanding around this workflow. This approach allows practitioners to find word vectors with such low overhead (dependency and mental overhead), and I am excited to keep working on it.