Mining CRAN DESCRIPTION Files
By Julia Silge
May 4, 2017
A couple of weeks ago, I saw on Dirk Eddelbuettel’s blog that R 3.4.0 was going to include a function for obtaining information about packages currently on CRAN, including basically everything in DESCRIPTION files. When R 3.4.0 was released, this was one of the things I was most immediately excited about exploring, because although I recently dabbled in scraping CRAN to try to get this kind of information, it was rather onerous.
library(tidyverse)
cran <- tools::CRAN_package_db()
# the returned data frame has two columns with the same name???
cran <- cran[,-65]
# make it a tibble
cran <- tbl_df(cran)
cran
## # A tibble: 10,542 × 64
## Package Version Priority Depends
## <chr> <chr> <chr> <chr>
## 1 A3 1.0.0 <NA> R (>= 2.15.0), xtable, pbapply
## 2 abbyyR 0.5.1 <NA> R (>= 3.2.0)
## 3 abc 2.1 <NA> R (>= 2.10), abc.data, nnet, quantreg, MASS, locfit
## 4 ABCanalysis 1.2.1 <NA> R (>= 2.10)
## 5 abc.data 1.0 <NA> R (>= 2.10)
## 6 abcdeFBA 0.4 <NA> Rglpk,rgl,corrplot,lattice,R (>= 2.10)
## 7 ABCoptim 0.14.0 <NA> <NA>
## 8 ABCp2 1.2 <NA> MASS
## 9 ABC.RAP 0.9.0 <NA> R (>= 3.1.0)
## 10 abcrf 1.5 <NA> R(>= 3.1)
## Imports LinkingTo
## <chr> <chr>
## 1 <NA> <NA>
## 2 httr, XML, curl, readr, plyr, progress <NA>
## 3 <NA> <NA>
## 4 plotrix <NA>
## 5 <NA> <NA>
## 6 <NA> <NA>
## 7 Rcpp Rcpp
## 8 <NA> <NA>
## 9 graphics, stats, utils <NA>
## 10 readr, MASS, ranger, parallel, stringr <NA>
## # ... with 10,532 more rows, and 58 more variables: Suggests <chr>, Enhances <chr>, License <chr>,
## # License_is_FOSS <chr>, License_restricts_use <chr>, OS_type <chr>, Archs <chr>, MD5sum <chr>,
## # NeedsCompilation <chr>, Additional_repositories <chr>, Author <chr>, `Authors@R` <chr>, Biarch <chr>,
## # BugReports <chr>, BuildKeepEmpty <chr>, BuildManual <chr>, BuildResaveData <chr>, BuildVignettes <chr>,
## # Built <chr>, ByteCompile <chr>, `Classification/ACM` <chr>, `Classification/ACM-2012` <chr>,
## # `Classification/JEL` <chr>, `Classification/MSC` <chr>, `Classification/MSC-2010` <chr>, Collate <chr>,
## # Collate.unix <chr>, Collate.windows <chr>, Contact <chr>, Copyright <chr>, Date <chr>, Description <chr>,
## # Encoding <chr>, KeepSource <chr>, Language <chr>, LazyData <chr>, LazyDataCompression <chr>, LazyLoad <chr>,
## # MailingList <chr>, Maintainer <chr>, Note <chr>, Packaged <chr>, RdMacros <chr>, SysDataCompression <chr>,
## # SystemRequirements <chr>, Title <chr>, Type <chr>, URL <chr>, VignetteBuilder <chr>, ZipData <chr>,
## # Published <chr>, Path <chr>, `X-CRAN-Comment` <chr>, `Reverse depends` <chr>, `Reverse imports` <chr>, `Reverse
## # linking to` <chr>, `Reverse suggests` <chr>, `Reverse enhances` <chr>
There you go, all the packages currently on CRAN!
Practices of CRAN maintainers
Some of the fields in the DESCRIPTION file of an R package tell us a bit about how a CRAN maintainer works, and in aggregate we can see how R package developers are operating.
How many packages have a URL, a place to go like GitHub to see the code and check out what is going on?
cran %>%
summarise(URL = mean(!is.na(URL)))
## # A tibble: 1 × 1
## URL
## <dbl>
## 1 0.4176627
What about a URL for bug reports?
cran %>%
summarise(BugReports = mean(!is.na(BugReports)))
## # A tibble: 1 × 1
## BugReports
## <dbl>
## 1 0.2165623
How many packages have a package designated as a VignetteBuilder?
cran %>%
count(VignetteBuilder, sort = TRUE)
## # A tibble: 23 × 2
## VignetteBuilder n
## <chr> <int>
## 1 <NA> 8633
## 2 knitr 1773
## 3 R.rsp 83
## 4 knitr, R.rsp 14
## 5 knitr, rmarkdown 7
## 6 highlight 6
## 7 utils, knitr 5
## 8 rmarkdown, knitr 3
## 9 packagedocs 2
## 10 R.rsp, 2
## # ... with 13 more rows
Are there packages that have vignettes but also have NA for VignetteBuilder? Yes, those would be packages that use
Sweave, the built-in vignette engine that comes with R. This must be biased toward older packages and it can’t be a large proportion of the total, given
when CRAN has been growing the fastest. I know there are still packages with Sweave vignettes, but these days, having something in VignetteBuilder is at least somewhat indicative of whether a package has a vignette. There isn’t anything else in the DESCRIPTION file, to my knowledge, that indicates whether a package has a vignette or not.
How many packages use testthat or RUnit for unit tests?
library(stringr)
cran %>%
mutate(tests = ifelse(str_detect(Suggests, "testthat|RUnit"), TRUE, FALSE),
tests = ifelse(is.na(tests), FALSE, tests)) %>%
summarise(tests = mean(tests))
## # A tibble: 1 × 1
## tests
## <dbl>
## 1 0.1950294
(Another handful of packages have these testing suites in Imports or Depends, but not enough to change that proportion much.)
Is it the same ~20% of packages that are embracing the practices of unit tests, building vignettes, and providing a URL for bug reports?
cran %>%
mutate(tests = ifelse(str_detect(Suggests, "testthat|RUnit"), TRUE, FALSE),
tests = ifelse(is.na(tests), FALSE, tests),
bug_report = ifelse(is.na(BugReports), FALSE, TRUE),
vignette = ifelse(is.na(VignetteBuilder), FALSE, TRUE)) %>%
count(tests, bug_report, vignette)
## # A tibble: 8 × 4
## tests bug_report vignette n
## <lgl> <lgl> <lgl> <int>
## 1 FALSE FALSE FALSE 6849
## 2 FALSE FALSE TRUE 594
## 3 FALSE TRUE FALSE 715
## 4 FALSE TRUE TRUE 328
## 5 TRUE FALSE FALSE 510
## 6 TRUE FALSE TRUE 306
## 7 TRUE TRUE FALSE 559
## 8 TRUE TRUE TRUE 681
Huh, so no, actually. I would have guessed that there would have been more packages in the TRUE/TRUE/TRUE bin in this data frame and fewer in the bins that are mixes of TRUE and FALSE. What does that distribution look like?
library(tidyr)
cran %>%
mutate(tests = ifelse(str_detect(Suggests, "testthat|RUnit"), "Tests", "No tests"),
tests = ifelse(is.na(tests), "No tests", tests),
bug_report = ifelse(is.na(BugReports), "No bug report", "Bug report"),
vignette = ifelse(is.na(VignetteBuilder), "No vignette builder", "Vignette builder")) %>%
count(tests, bug_report, vignette) %>%
mutate(percent = n / sum(n)) %>%
arrange(desc(percent)) %>%
unite(practices, tests, bug_report, vignette, sep = "\n") %>%
mutate(practices = reorder(practices, -percent)) %>%
ggplot(aes(practices, percent, fill = practices)) +
geom_col(alpha = 0.7, show.legend = FALSE) +
scale_y_continuous(labels = scales::percent_format()) +
labs(x = NULL, y = "% of CRAN pacakges",
title = "How many packages on CRAN have units tests, a URL for bug reports, or a vignette builder?",
subtitle = "About 6% of packages currently on CRAN have all three")
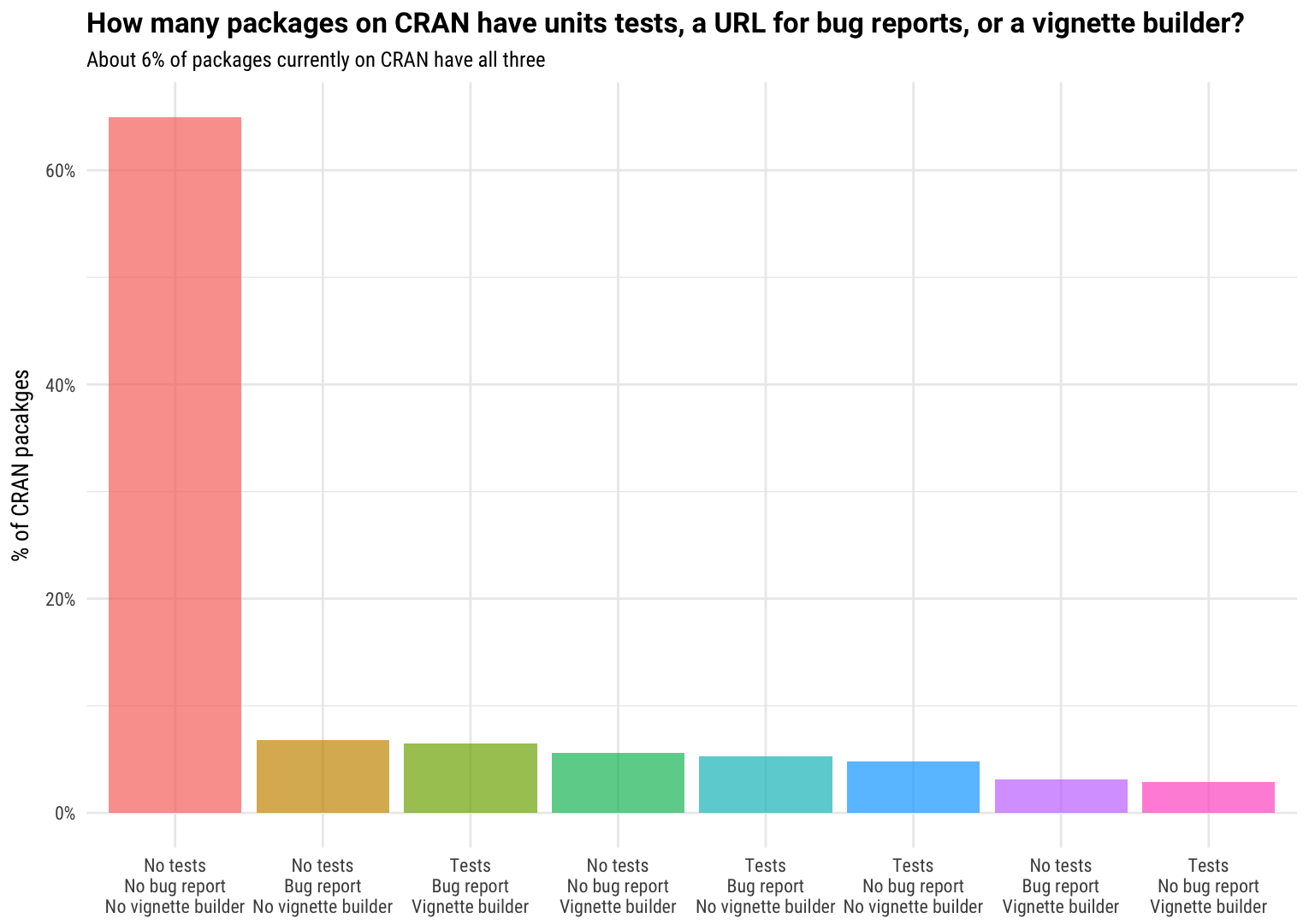
Maybe I should not be surprised, since a package that I myself maintain has unit tests and a URL for bug reports but no vignette. And remember that a few of the “No vignette builder” packages are maintainers choosing to produce vignettes via Sweave, OLD SCHOOL.
Yo dawg I heard you like Descriptions in your DESCRIPTION
One of the fields in the DESCRIPTION file for an R package is the Description for the package.
cran %>%
filter(Package == "tidytext") %>%
select(Description)
## # A tibble: 1 × 1
## Description
## <chr>
## 1 Text mining for word processing and sentiment analysis using\n 'dplyr', 'ggplot2', and other tidy tools.
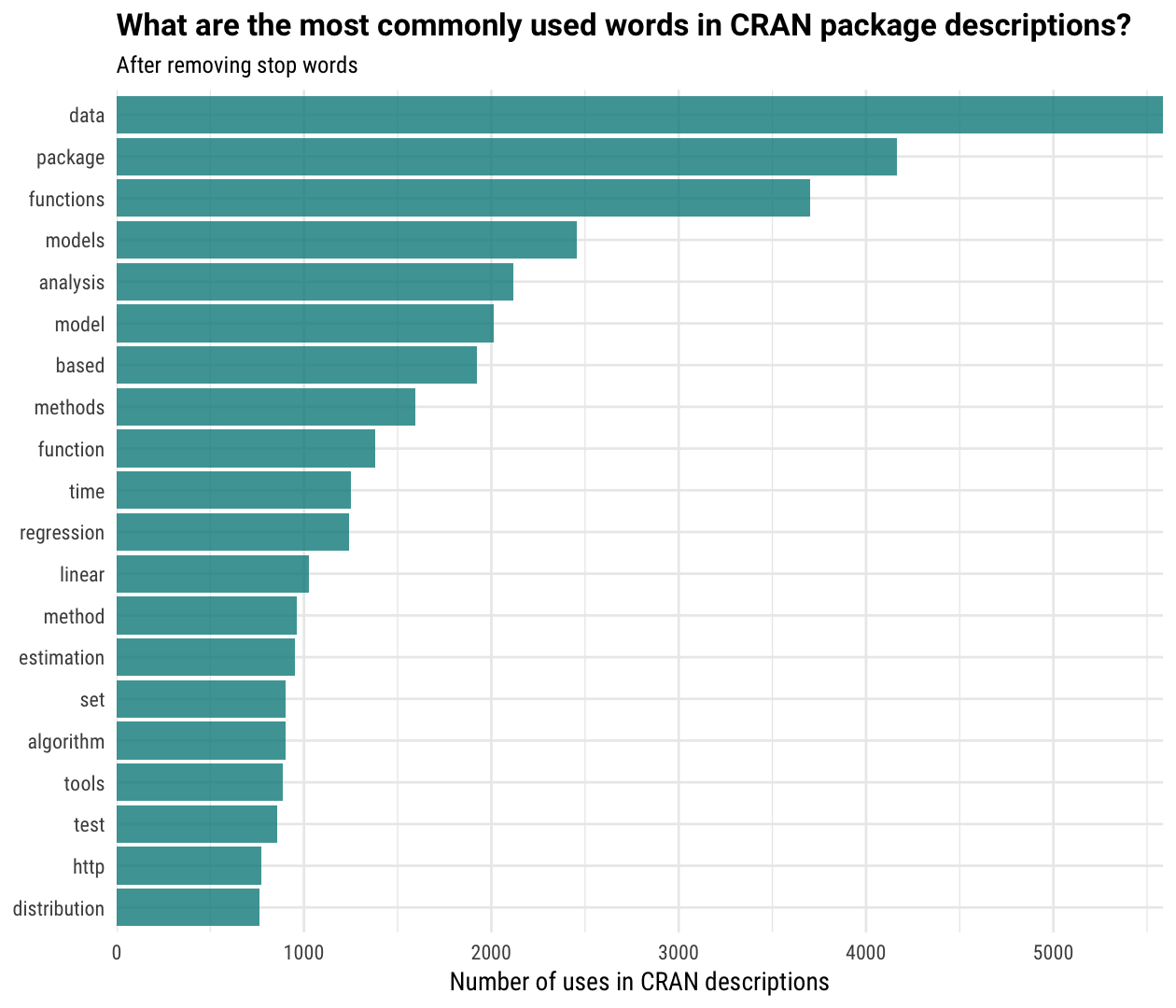
Let’s use the tidytext package that I have developed with David Robinson to take a look at the words maintainers use to describe their packages. What words do they use the most often?
library(tidytext)
tidy_cran <- cran %>%
unnest_tokens(word, Description)
word_totals <- tidy_cran %>%
anti_join(stop_words) %>%
count(word, sort = TRUE)
word_totals %>%
top_n(20) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_col(fill = "cyan4", alpha = 0.8) +
coord_flip() +
scale_y_continuous(expand = c(0,0)) +
labs(x = NULL, y = "Number of uses in CRAN descriptions",
title = "What are the most commonly used words in CRAN package descriptions?",
subtitle = "After removing stop words")
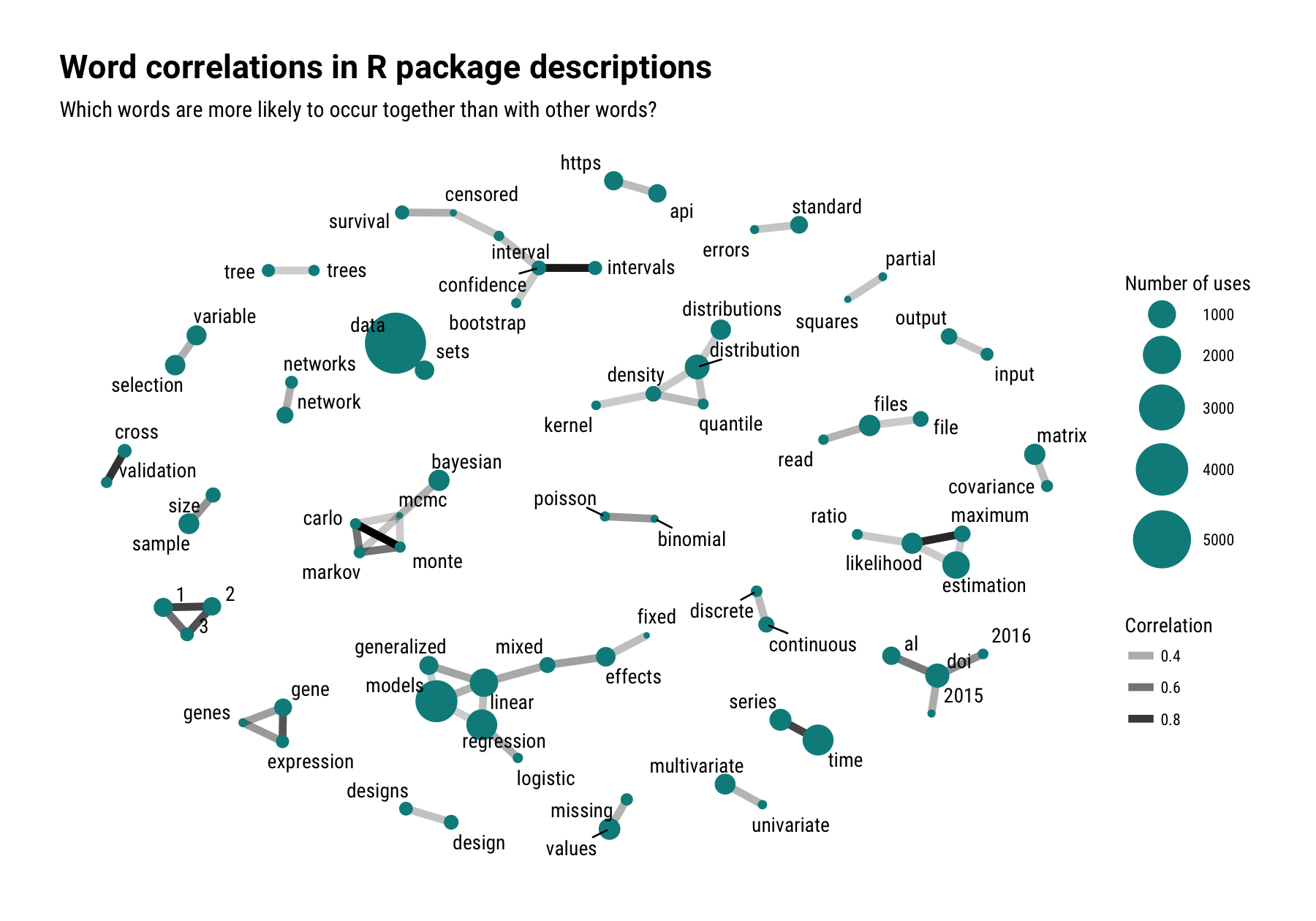
Now let’s see what the relationships between all these description words are. Let’s look at how words are correlated together within description fields and make a word network.
library(igraph)
library(ggraph)
library(widyr)
word_cors <- tidy_cran %>%
anti_join(stop_words) %>%
group_by(word) %>%
filter(n() > 150) %>% # filter for words used at least 150 times
ungroup %>%
pairwise_cor(word, Package, sort = TRUE)
filtered_cors <- word_cors %>%
filter(correlation > 0.2,
item1 %in% word_totals$word,
item2 %in% word_totals$word)
vertices <- word_totals %>%
filter(word %in% filtered_cors$item1)
set.seed(1234)
filtered_cors %>%
graph_from_data_frame(vertices = vertices) %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = correlation), width = 2) +
geom_node_point(aes(size = n), color = "cyan4") +
geom_node_text(aes(label = name), repel = TRUE, point.padding = unit(0.2, "lines"),
family = "RobotoCondensed-Regular") +
theme_graph(base_family = "RobotoCondensed-Regular") +
theme(plot.title=element_text(family="Roboto-Bold")) +
scale_size_continuous(range = c(1, 15)) +
labs(size = "Number of uses",
edge_alpha = "Correlation",
title = "Word correlations in R package descriptions",
subtitle = "Which words are more likely to occur together than with other words?")
The End
If you are interested in this approach to text analysis in R, check out the book Dave and I are publishing with O’Reilly, to be released this summer, available online as well. I found it really interesting to get a glimpse into this ecosystem that is such an important part of my professional and open-source life, both to see the overlap with the areas that I work in and the vast areas that I do not! The R Markdown file used to make this blog post is available here. I am very happy to hear feedback and questions!