Punctuation in literature
By Julia Silge
June 30, 2018
This morning I was scrolling through Twitter and noticed Alberto Cairo share this lovely data visualization piece by Adam J. Calhoun about the varying prevalence of punctuation in literature. I thought, “I want to do that!” It also offers me the opportunity to chat about a few of the new options available for tokenizing in tidytext via updates to the tokenizers package.
Adam’s original piece explores how punctuation is used in nine novels, including my favorite Pride and Prejudice. To mix things up a bit, let’s include some of the same pieces of literature Adam used and some different ones. We can access the full text of public domain works from Project Gutenberg via the gutenbergr package.
library(tidyverse)
library(gutenbergr)
titles <- c("Pride and Prejudice",
"Ulysses",
"Anne of Green Gables",
"Wuthering Heights",
"The War of the Worlds",
"Alice's Adventures in Wonderland",
"Adventures of Huckleberry Finn",
"Frankenstein; Or, The Modern Prometheus",
"The Strange Case of Dr. Jekyll and Mr. Hyde")
books <- gutenberg_works(title %in% titles) %>%
gutenberg_download(meta_fields = "title") %>%
mutate(text = iconv(text, from = "latin1", to = "UTF-8"))
books## # A tibble: 100,286 x 3
## gutenberg_id text title
## <int> <chr> <chr>
## 1 11 ALICE'S ADVENTURES IN WONDERLAND Alice's Adventures in …
## 2 11 "" Alice's Adventures in …
## 3 11 Lewis Carroll Alice's Adventures in …
## 4 11 "" Alice's Adventures in …
## 5 11 THE MILLENNIUM FULCRUM EDITION 3.0 Alice's Adventures in …
## 6 11 "" Alice's Adventures in …
## 7 11 "" Alice's Adventures in …
## 8 11 "" Alice's Adventures in …
## 9 11 "" Alice's Adventures in …
## 10 11 CHAPTER I. Down the Rabbit-Hole Alice's Adventures in …
## # ... with 100,276 more rowsWe now have the full texts of these works. Next, let’s find the punctuation that is used in each. In some recent releases of tidytext (in addition to A STICKER) we have support for more kinds of tokenizing, including tokenization for tweets and options for handling punctuation. Let’s keep punctuation, instead of throwing it out, and then filter to only keep the punctuation tokens we want.
library(tidytext)
punctuation <- books %>%
unnest_tokens(token, text, strip_punct = FALSE) %>%
count(title, token, sort = TRUE) %>%
filter(token %in% c(",", "?", ".", '"', "'", "!", ";", ":"))
punctuation## # A tibble: 70 x 3
## title token n
## <chr> <chr> <int>
## 1 Ulysses . 22178
## 2 Ulysses , 16361
## 3 Wuthering Heights , 9892
## 4 Pride and Prejudice , 9132
## 5 Adventures of Huckleberry Finn , 8050
## 6 Anne of Green Gables . 6567
## 7 Pride and Prejudice . 6180
## 8 Anne of Green Gables , 5505
## 9 Wuthering Heights . 5141
## 10 Adventures of Huckleberry Finn . 5098
## # ... with 60 more rowsNow we can make a bar chart like the one in the original piece to compare how punctuation is used in these nine pieces of literature.
punctuation %>%
mutate(token = reorder(token, n),
title = case_when(str_detect(title, "Frankenstein") ~ "Frankenstein",
str_detect(title, "Dr. Jekyll") ~ "Dr. Jekyll and Mr. Hyde",
TRUE ~ title)) %>%
ggplot(aes(token, n, fill = title)) +
geom_col(alpha = 0.8, show.legend = FALSE) +
coord_flip() +
facet_wrap(~title, scales = "free_x") +
scale_y_continuous(expand = c(0,0)) +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.text.y = element_text(family = "IBMPlexSans-Bold",
size = 14)) +
labs(x = NULL, y = NULL,
title = "Punctuation in literature",
subtitle = "Commas are typically most common")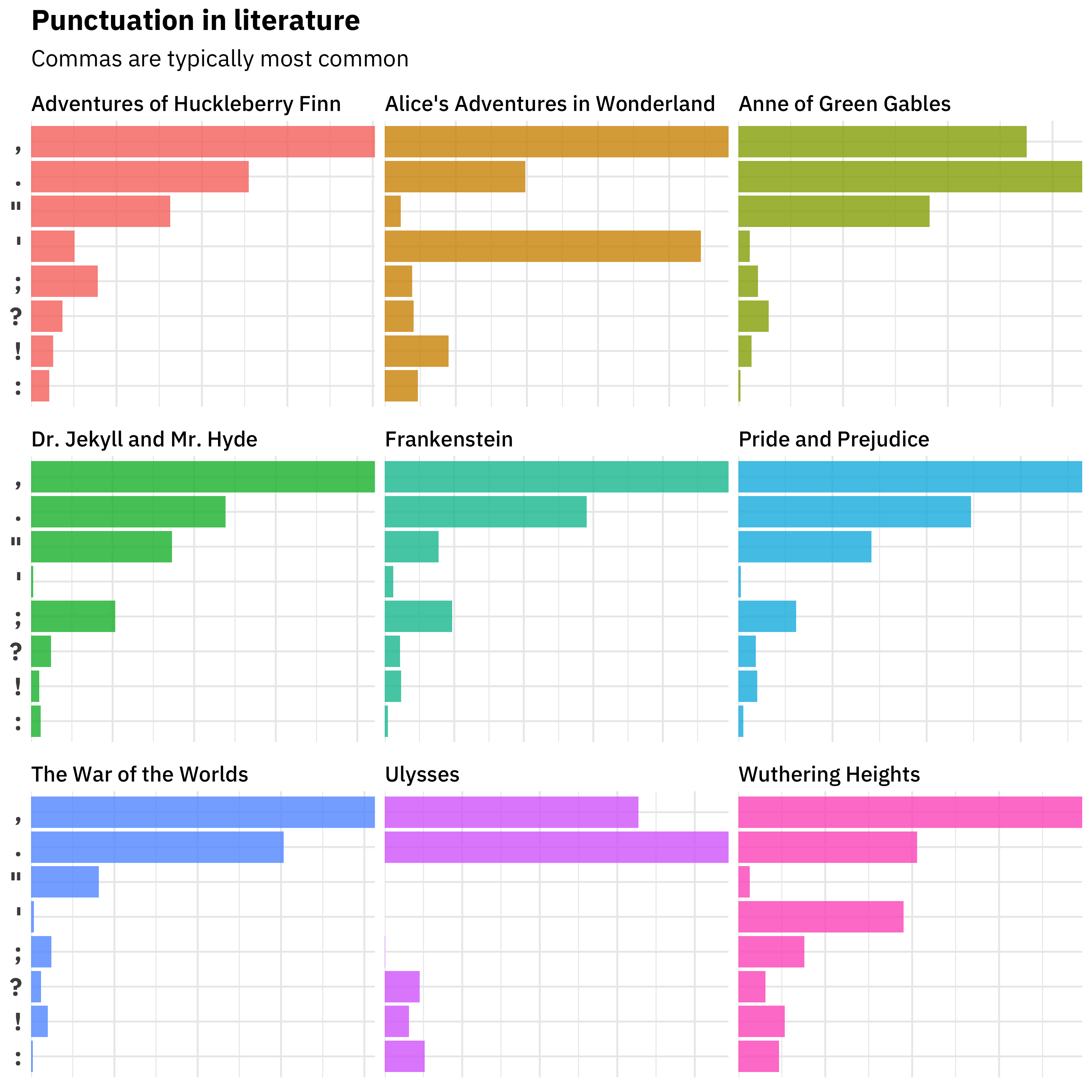
Commas are the PUNCTUATION WINNER, except in Anne of Green Gables and Ulysses, where periods win out. These two novels are dramatically different from each other in other ways, though, and Ulysses is an outlier overall with almost no spoken dialogue via quotation marks and an unusual use of colons to semicolons. Exclamation marks are used relatively more in Wuthering Heights and Alice in Wonderland!
Exploring text in these kinds of ways is so fun, and tools for this type of text mining are developing so fast. You can incorporate information like this into modeling or statistical analysis; Mike Kearney has a package called textfeatures that lets you directly extract info such as the number of commas or number of exclamation marks from text. Let me know if you have any questions!