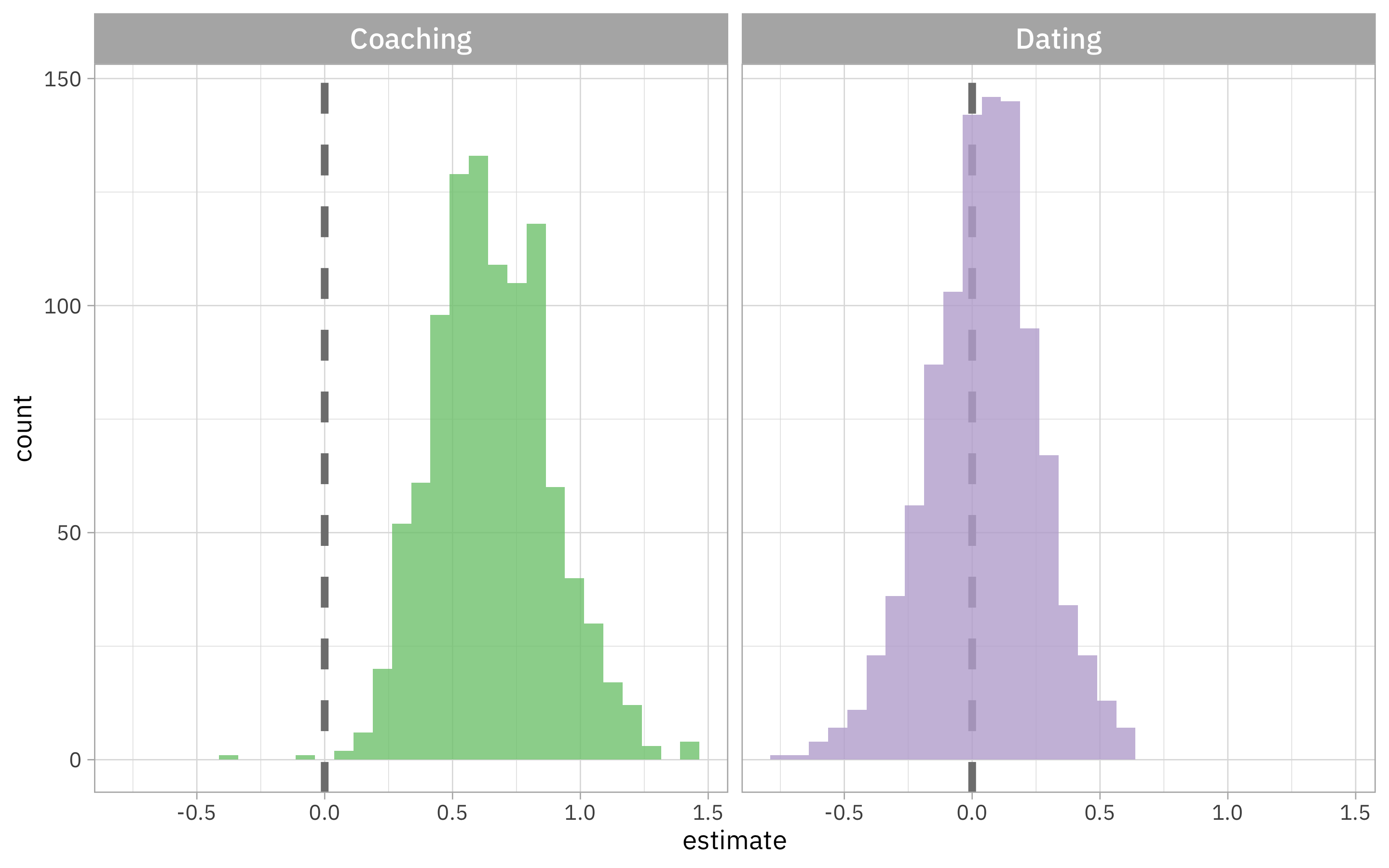
How often does Roy Kent say “F*CK”?
He’s here, he’s there, he’s every f*cking where, and we’re finding bootstrap confidence intervals.
Machine learning, text analysis, and more
He’s here, he’s there, he’s every f*cking where, and we’re finding bootstrap confidence intervals.
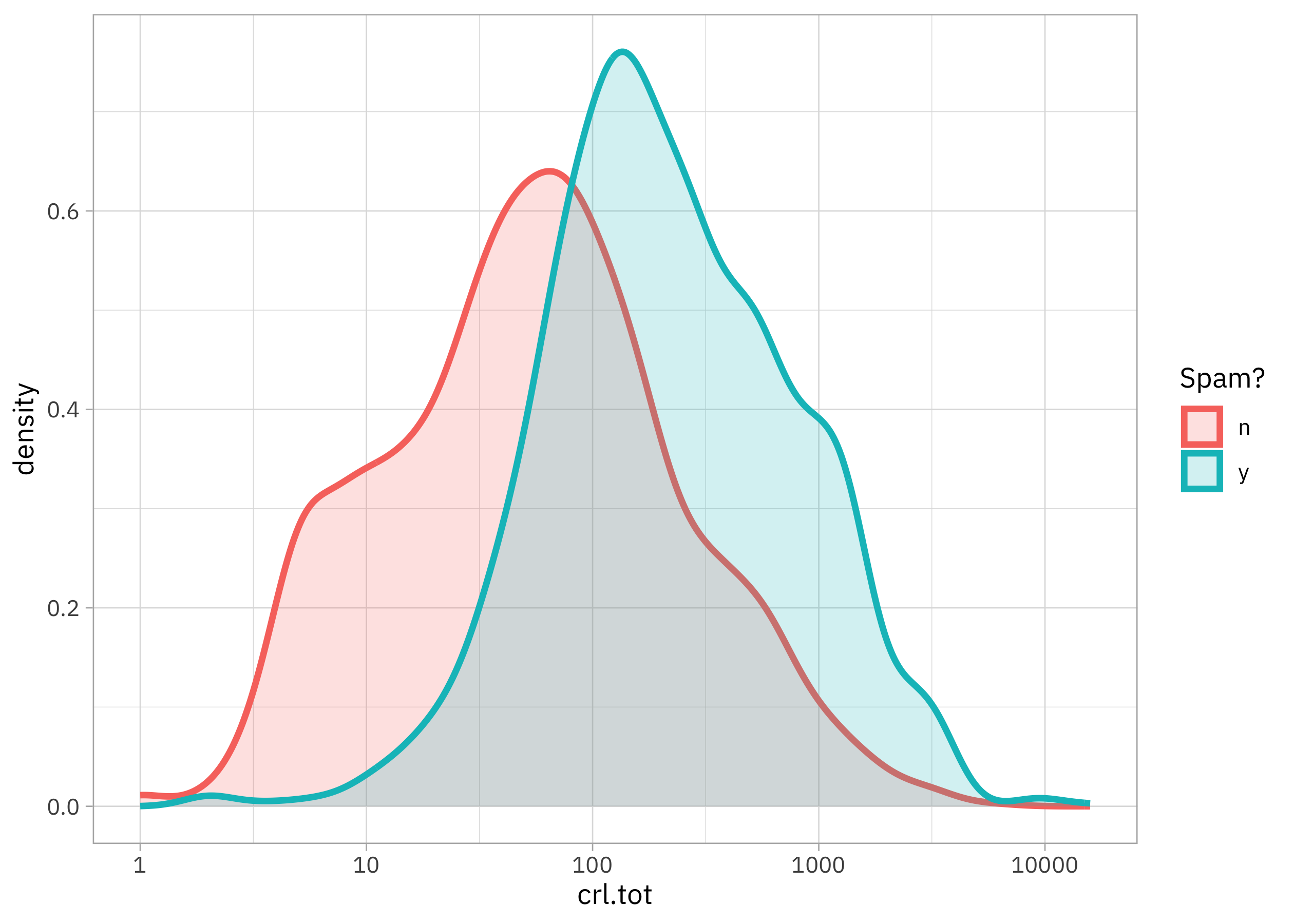
Use workflowsets to evaluate multiple possible models to predict whether email is spam.
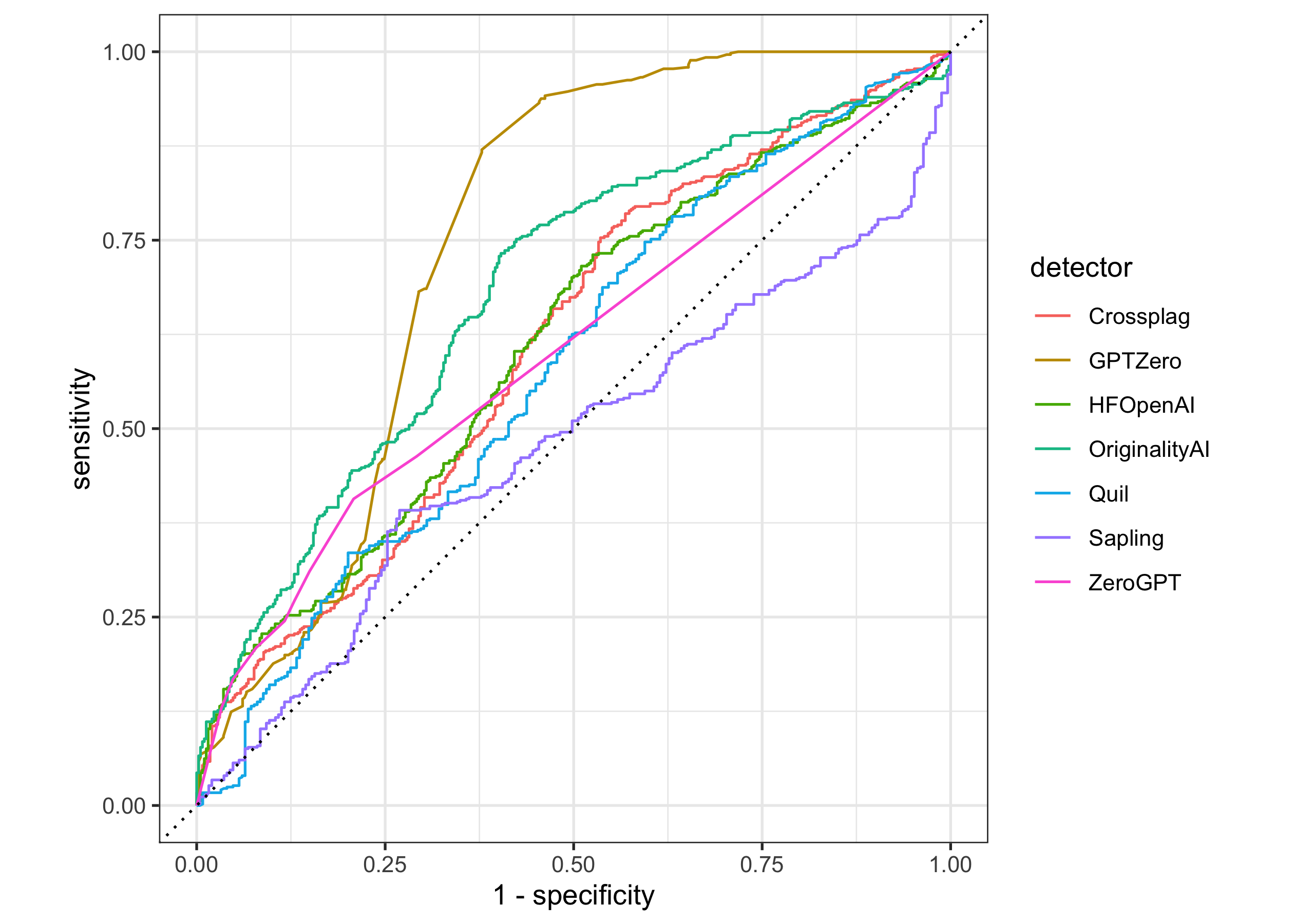
Learn about different kinds of metrics for evaluating classification models, and how to compute, compare, and visualize them.
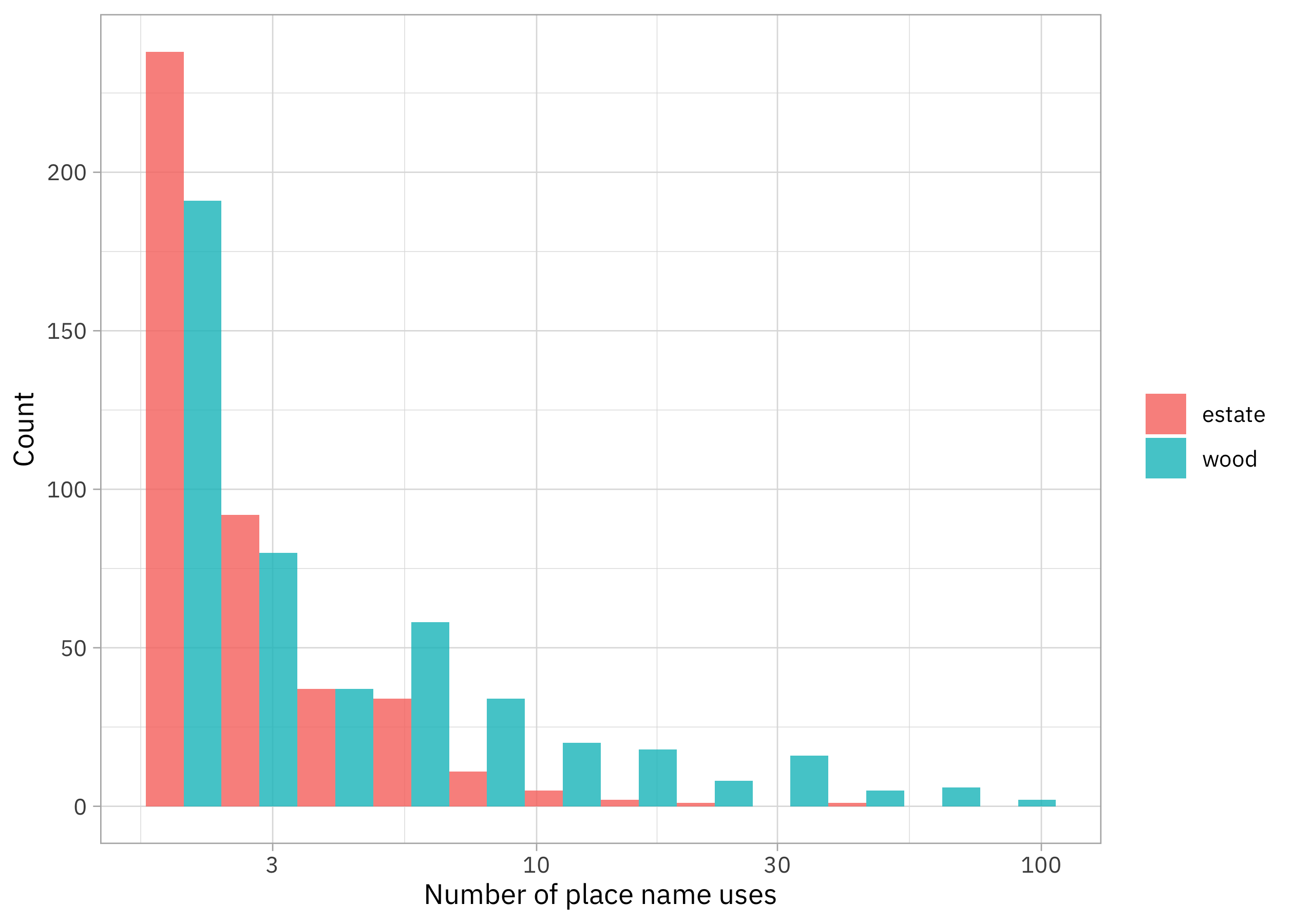
Let’s use byte pair encoding tokenization along with Poisson regression to understand which tokens are more more often (or less often) in US place names.
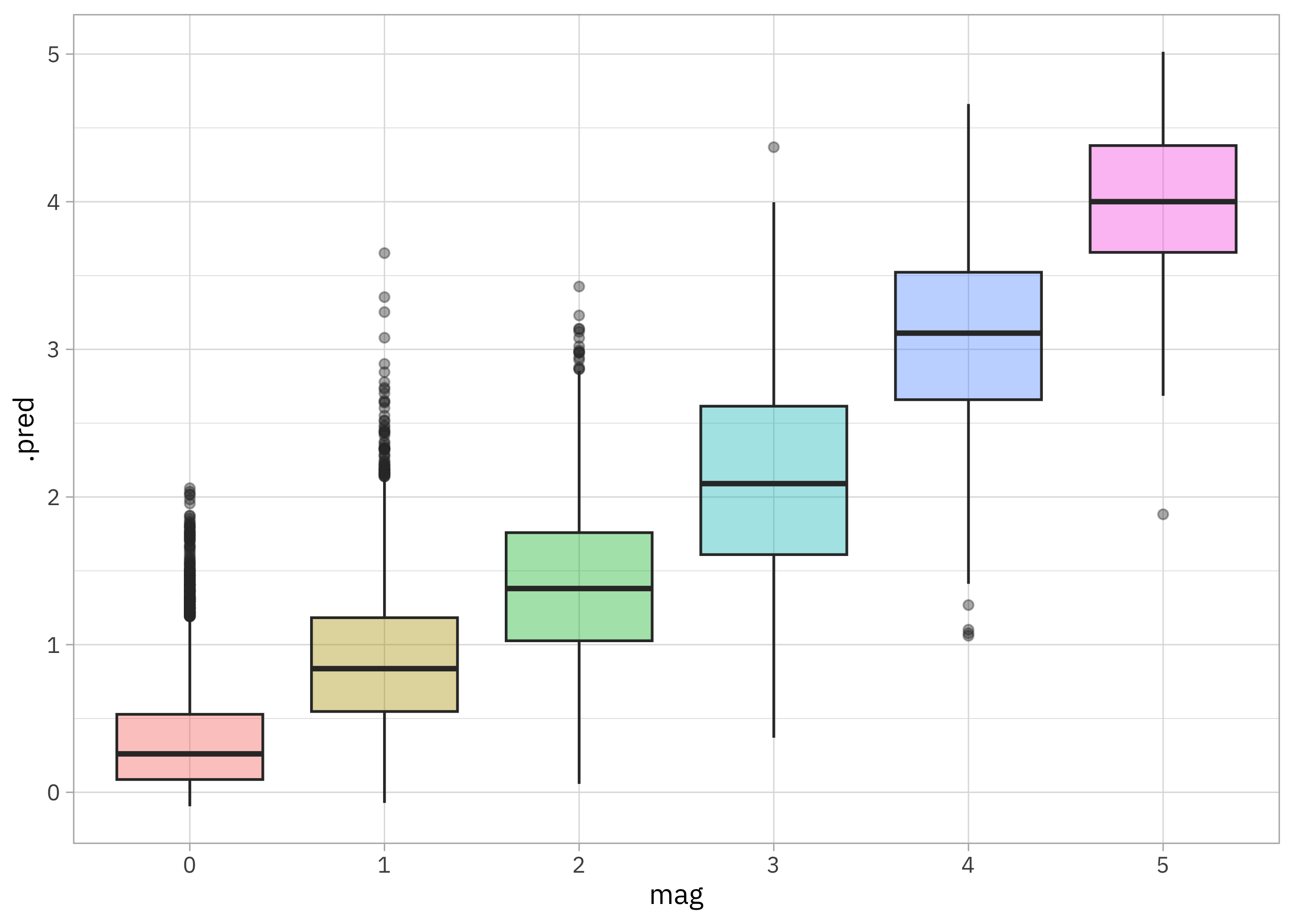
How well can we predict the magnitude of tornadoes in the US? Let’s use xgboost along with effect encoding to fit our model.